
Bringing AI and LLMs into healthcare has the potential to really change the game.
Imagine speeding up research, making clinical workflows smoother, and ultimately helping patients get better care faster.
Sounds great, right?
But it’s not that simple; there are real challenges around privacy, security, and rules hospitals have to follow.
Using cloud-based AI might seem convenient, but it comes with big risks. Data could leak, and you’re stuck relying on a vendor, something that hospitals and research centers just can’t afford. That’s why an offline, on-premise approach makes so much sense. Keep everything in-house, under your control.
Here’s how it could work: use open-source LLMs like Llama, managed with tools like Ollama or HuggingFace. Add a local “smart memory” system (a Retrieval-Augmented Generation pipeline with ObjectBox) to keep your data private but accessible. And the interface? Something flexible like OpenWebUI that your clinical team can actually use without frustration.
The big win: better control over your data, stronger compliance with rules like HIPAA, and no getting locked into a vendor. Of course, it’s not plug-and-play; you’ll need powerful computers and a skilled team.
But if you do it right, it’s a game-changer. The AI doesn’t replace doctors or researchers; it helps them work smarter, make faster decisions, and keep sensitive data safe. With the right processes, training, and oversight, this setup can bring all the benefits of Generative AI without the scary risks.
In this article, we’ll show how an offline, on-premise setup can give clinical teams the power of AI. This blueprint covers the technical design, tools, and workflows needed to make AI a helpful assistant.
What Makes Offline AI Essential for Healthcare Privacy and Security?
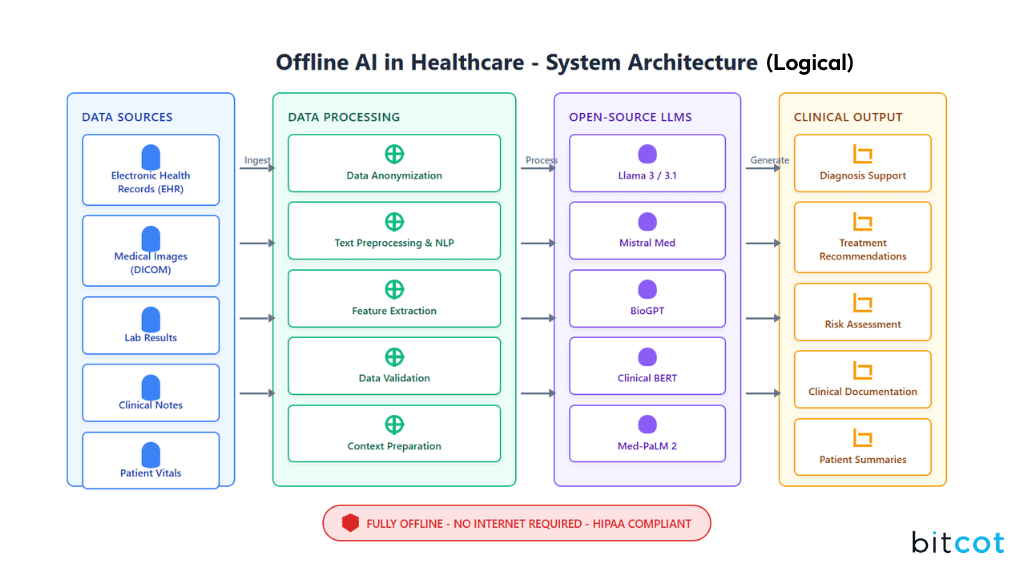
When it comes to healthcare, protecting patient data isn’t just a best practice; it’s the law. Cloud-based AI tools can be convenient, but they also introduce risks like data leaks, vendor dependence, and compliance headaches.
That’s why offline, on-premise AI is becoming essential.
By keeping AI systems local, healthcare organizations can take control of sensitive information, ensure regulatory compliance, and reduce reliance on external providers.
In the following sections, we’ll break down why moving away from cloud APIs, choosing an on-premise architecture, and leveraging open-source LLMs like Llama can make healthcare AI both powerful and safe.
Why Should Healthcare Shift from Cloud APIs to On-Premise AI Models?
AI and LLMs are evolving fast and have huge potential in healthcare, from helping with clinical decisions to making sense of complex medical text. But most of these tools are still accessed through cloud-based, proprietary models.
Sure, they’re easy to use, but they come with big risks: sensitive patient data leaves your control, vendor dependence grows, and even the strongest legal agreements can’t fully eliminate the possibility of leaks. Real-world incidents of confidential data slipping into public LLMs show just how serious this risk can be.
Shifting to an on-premise, offline-first approach changes the game. Instead of outsourcing responsibility to a cloud provider, all AI processing and storage happens inside your own network. That means full control over sensitive patient data and peace of mind that it never leaves a secure environment.
There’s also a financial benefit. Instead of paying for every API call, which can get expensive quickly, you invest upfront in hardware and a skilled in-house team. Over time, this makes costs more predictable and can even be more cost-effective at scale.
Finally, a cloud-neutral design ensures you’re not locked into a single vendor. Your system can adapt to regulatory changes and new technology, giving your organization the flexibility it needs to plan long-term in a highly regulated, high-stakes environment.
Why is an On-Premise Architecture Best for Compliance?
Any AI system that deals with Protected Health Information (PHI) has to follow strict privacy rules, like HIPAA in the U.S. An on-premise, offline-first setup is built with these rules in mind; it puts privacy and security at the core.
Some key features that make an on-premise system HIPAA-ready include:
- End-to-End Encryption: All data, whether it’s moving across the network or stored, is protected with strong encryption like AES-256.
- Role-Based Access Control (RBAC): Only the right people can access specific data, with multi-factor authentication adding an extra layer of security.
- Comprehensive Audit Logging: Every action is logged in detail, making compliance reporting and forensic analysis straightforward.
- Data Loss Prevention (DLP): Systems and policies prevent sensitive information from leaving authorized channels.
Going fully offline, air-gapped, with no external internet connection, offers the strongest protection. All AI processing happens locally, keeping data under full control. For high-stakes healthcare environments, this approach minimizes the risk of accidental leaks, regulatory penalties, and costly breaches, giving both clinicians and patients peace of mind.
Why Choose Open-Source LLMs like Llama to Enhance Healthcare AI?

Open-source LLMs, like those in the Llama family, give healthcare organizations a level of control that proprietary models simply can’t match. When you have access to the code, model weights, and training data, you can fine-tune outputs and adapt the model to highly specific healthcare needs, something crucial in a field where nuances can make all the difference.
The open-source community is actively innovating in healthcare AI. For example, Llama-based models like OpenBioLLM help streamline complex tasks in clinical trials, such as protocol creation and document analysis.
Another model, Me-LLaMA, was trained on one of the largest medical datasets and has been shown to outperform even leading commercial models like ChatGPT and GPT-4 on specialized medical text tasks. This proves that open-source models can be highly effective when properly adapted to domain-specific needs.
There’s also a strategic advantage: open-source frameworks avoid vendor lock-in, giving organizations freedom from proprietary pricing structures, API changes, or reliance on a single provider. This flexibility supports long-term operational resilience and encourages a culture of innovation within the organization.
Finally, when deployed on-premise, open-source LLMs maximize security and control. Data stays inside the local network, reducing internet dependency and vendor risk. While this setup requires significant in-house expertise and investment in hardware, it offers superior data privacy, long-term cost predictability, and the ability to tailor AI tools exactly to the organization’s needs.
In contrast, cloud-based models offer easier deployment but come with higher operational costs, ongoing vendor dependence, and reduced control over sensitive data.
What Core Architectural Components Power Offline Healthcare AI Systems?
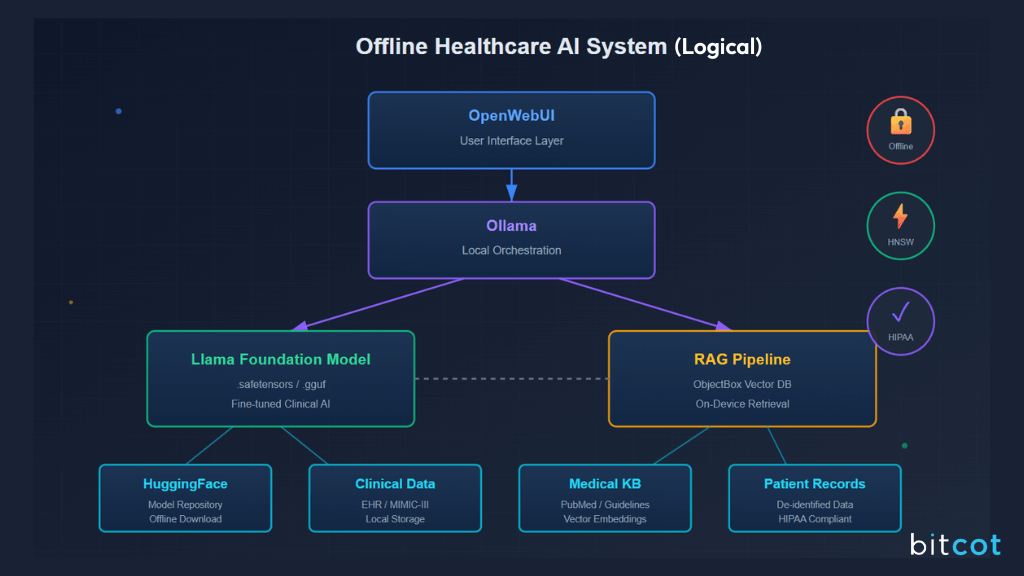
Building an offline AI system for healthcare isn’t just about picking a few tools; it’s about designing a layered ecosystem where every component has a clear role. Each part strengthens the others, creating a system that’s reliable, flexible, and ready for long-term clinical use.
This modular approach is key: it allows healthcare organizations to adapt, scale, and maintain control over their AI systems while ensuring they meet the high standards of privacy, security, and performance required in clinical environments.
How are Llama Foundation Models Selected and Fine-Tuned for Clinical Use?
The Llama family of models provides a strong, open-source foundation for healthcare AI, but a general-purpose model alone isn’t enough for the highly specialized needs of a clinical environment.
The real strength of Llama comes from domain-specific adaptation, which tailors the model to understand and respond accurately to medical and clinical tasks.
This adaptation happens in two key stages:
- Continual Pretraining: The base model is fine-tuned on large amounts of domain-specific data; think biomedical research papers, clinical notes, and medical guidelines. For example, the Me-LLaMA project used over 129 billion tokens from sources like PubMed Central and de-identified clinical notes from MIMIC-III to teach the model medical knowledge.
- Instruction Tuning: After pretraining, the model is further refined to follow instructions and generate high-quality, task-specific responses. This uses a carefully curated dataset of clinical and biomedical instruction-following examples.
Together, these steps produce a model that can outperform general-purpose LLMs, and even some larger proprietary models, on healthcare-specific benchmarks.
The takeaway?
In healthcare AI, the real investment isn’t just in picking the model; it’s in the careful work of curating and preparing the data that makes the model truly clinically useful.
How Do Local Orchestration Tools Enable Fully Offline Healthcare AI?
To keep healthcare AI truly offline, the architecture relies on local orchestration tools that run LLMs directly on your own hardware, so sensitive data never leaves the system.
One key tool is Ollama, a lightweight, developer-friendly platform that makes running LLMs locally simple.
Its main benefits include:
- Offline Operation: Ollama doesn’t need the cloud or internet, making it perfect for privacy-sensitive, air-gapped environments.
- Privacy-First Design: All AI tasks run locally, giving full control over data and helping meet HIPAA and other regulatory requirements.
- Developer-Oriented Interface: Its command-line interface makes it easy to build automated pipelines for clinical workflows.
HuggingFace complements this setup by serving as the main hub for open-source AI models. While often associated with cloud services, it’s also the go-to place to download models and tokenizer files for offline use.
You simply download the models on a connected machine and configure your system to load them locally. HuggingFace also hosts medical-specific models like MedGemma, which can be integrated seamlessly into an offline clinical AI workflow.
Together, tools like Ollama and HuggingFace make it possible to run a fully offline, high-performance AI system in hospitals or research environments, combining flexibility, privacy, and clinical readiness.
How Does a RAG Pipeline Use ObjectBox for Offline Data Retrieval?
One limitation of any LLM, whether on-premise or cloud-based, is that its knowledge is “frozen” at the point when it was last trained. That means it might miss new developments or organization-specific information.
This is where a Retrieval-Augmented Generation (RAG) pipeline comes in.
RAG connects the LLM to a real-time, trusted knowledge base, ensuring that responses are accurate, traceable, and grounded in current, proprietary data. By integrating ObjectBox as a local vector store, the system can quickly retrieve relevant documents or data points directly from the organization’s internal resources, all while staying completely offline.
This setup reduces the risk of “hallucinations,” keeps sensitive information secure, and allows the LLM to provide actionable insights based on the organization’s own critical data.
Essentially, RAG transforms a static model into a dynamic, context-aware assistant without ever leaving the secure environment.
How Does a RAG Pipeline Enable AI in a Clinical Context?
The RAGnosis framework is a great example of how a clinical RAG workflow can operate fully on-premise. A key part of this setup is ObjectBox, an on-device vector database designed for speed and efficiency even on standard hardware.
ObjectBox enables a completely offline RAG workflow with features like:
- On-Device Vector Search: Using the HNSW algorithm, ObjectBox can find semantically similar data in milliseconds across millions of entries, right on the device. This brings powerful local AI capabilities to edge environments like hospital networks or clinical devices.
- Offline-First Sync: All data is stored locally, so the system works entirely offline. When a connection is available, ObjectBox Sync updates only the changes to a central server hosted on-premise, keeping data movement minimal and secure.
This approach ensures sensitive clinical data never leaves the local environment, while still allowing the AI to provide fast, context-aware responses, exactly what clinicians need for decision-making and patient care.
How Does OpenWebUI Enable User Interface Customization for Healthcare Teams?
OpenWebUI is a flexible web interface that bridges the gap between complex backend AI systems and healthcare professionals. By integrating seamlessly with local LLM backends like Ollama, it creates a user-friendly environment tailored to clinical workflows.
Key features designed for regulated healthcare environments include:
- Local Knowledge Base Integration: The “Knowledge” feature acts as a memory bank where structured information and documents can be stored. Clinicians can reference this data directly in chats using simple commands, triggering the RAG pipeline to pull in the relevant information.
- Custom Scripts and Pipelines: The “Pipelines” framework allows healthcare teams to add custom logic, integrate Python libraries, or build specialized RAG workflows. This flexibility makes it easy to enforce function calling or integrate with existing clinical systems.
- Admin-Level Security Controls: OpenWebUI supports user roles (pending, user, admin) to manage access and permissions, ensuring the system aligns with an organization’s security and governance policies.
Together, these features make OpenWebUI a practical, secure, and adaptable interface that allows healthcare teams to interact effectively with offline AI systems without compromising privacy or compliance.
How Do .safetensors and .gguf Model Formats Affect LLM Portability and Efficiency?
Choosing the right model format isn’t a trivial decision; it directly impacts security, startup time, and portability. Two widely used formats, .safetensors and .gguf, serve distinct purposes and offer different trade-offs across the LLM deployment lifecycle.
.safetensors
This is a tensor-only, memory-mappable format designed for speed and security. It’s the default serialization format used by Hugging Face’s transformers library. Its main advantage is safety: it stores only named tensors along with a JSON header, which prevents the execution of arbitrary code during loading.
This makes it ideal for securely sharing or distributing models in professional and regulated environments.
.gguf
Originally developed for the llama.cpp project, this binary format is optimized for fast, CPU-based inference on commodity hardware. Its flexible quantization schemes can reduce memory usage and significantly speed up offline performance.
The .gguf format is mainly used in production environments where fast loading times are essential, particularly on resource-constrained devices like laptops or embedded systems.
Both Formats
In practice, an organization’s deployment pipeline often leverages both formats. A fine-tuned model can first be saved as a .safetensors file for secure storage and distribution, and then converted to a quantized .gguf format for fast, efficient on-premise use. This layered approach balances security, performance, and portability, showcasing a sophisticated understanding of the full LLM lifecycle.
Within this ecosystem:
- Llama LLM provides the foundational AI for text understanding and generation, offering high performance, customization, and community-driven innovation.
- Ollama orchestrates local inference with offline capability, privacy by design, and developer-friendly controls.
- HuggingFace serves as the central repository for accessing and managing open-source models, supporting offline deployment.
- ObjectBox is the on-device vector database for storing knowledge base embeddings, enabling privacy-preserving RAG, fast retrieval, and lightweight operation on-premise.
- OpenWebUI acts as the user-facing interface, offering friendly, customizable workflows, local knowledge integration, and regulated script-based pipelines for clinical teams.
This combination ensures that every component, from the model format to the user interface, is optimized for offline, secure, and high-performance healthcare AI deployments.
Use Cases and Strategies for Practical Implementation of LLMs in Healthcare

The strategic and technical choices outlined in the previous sections open the door to real-world, high-impact applications in hospitals and clinical research environments. This framework is especially well-suited for scenarios where sensitive, proprietary data must stay within a controlled, compliant environment.
In this section, we’ll explore how healthcare organizations can leverage offline LLMs effectively, highlighting practical use cases and strategies for integrating these AI systems into daily clinical workflows without compromising security, privacy, or compliance.
How to Accelerate Clinical Trials and Research with Offline RAG
Biomedical literature and clinical trial documents are growing at an overwhelming pace, creating a major bottleneck for researchers. An offline RAG system can act as a “Medical Insights Miner,” quickly retrieving and synthesizing information from massive document collections, all without relying on cloud APIs.
Key applications include:
- Automated Literature Review: The system can scan thousands of biomedical publications, organizing and summarizing key findings on specific drugs, diseases, or genes. This saves researchers hours of manual work and keeps them up-to-date with the latest studies.
- Clinical Trial Document Analysis: By indexing a hospital’s internal repository of clinical trial documents, the RAG system accelerates extraction of insights from complex, semi-structured data. This supports tasks like protocol generation and detailed data analysis, helping bring new treatments to patients faster.
The real power comes from grounding the LLM in proprietary organizational data, such as internal study reports or institutional clinical guidelines. Without a high-quality, curated knowledge base, even the best LLM cannot perform optimally. Investing time to curate, clean, and structure internal data is essential for a RAG system to deliver accurate, actionable insights in a clinical research context.
How Can On-Premise RAG Streamline EHR Analysis and Clinical Documentation?
Electronic Health Records (EHRs) are essential in modern healthcare, but their mix of structured data and unstructured clinical notes makes analysis challenging. An on-premise RAG framework is perfectly suited to handle this complexity while keeping data secure.
The RAGnosis framework is a great example. Designed for offline, on-premise operation, it combines OCR, a local vector database, and an instruction-tuned LLM to interpret unstructured clinical text. Here’s how it works in practice:
- Ingestion & OCR: Raw cardiology reports or other clinical documents are converted from PDFs or other formats into plain text for processing.
- Embedding & Retrieval: Important clinical information is turned into semantic embeddings and stored locally. When a clinician submits a query, the system quickly retrieves the most relevant segments.
- Generation: The locally hosted LLM synthesizes the retrieved information into evidence-backed answers, complete with in-text citations for accuracy and traceability.
This modular, living architecture allows a hospital to continuously learn from new patient reports and medical literature, building a dynamic system for clinical decision support that is both secure and fully compliant.
How Can Human-in-the-Loop RAG Systems Enhance Clinical Decision Support?
Research consistently emphasizes that LLMs should augment healthcare professionals, not replace them. A human-in-the-loop approach ensures that AI assists clinicians while human oversight remains central, maintaining safety, accountability, and trust.
Key implementations include:
- Clinical Decision Support: The RAG system can help with diagnostics by retrieving precise medical data, generating tailored treatment suggestions from patient records, and cross-referencing established clinical guidelines. This allows clinicians to make faster, more informed decisions without relinquishing control.
- Multi-Agent RAG Systems: Advanced setups can use a network of specialized AI agents, each handling tasks like diagnostic support, insurance verification, or documentation review. These agents interact with hospital systems to deliver coordinated, explainable, and auditable responses, mirroring the teamwork and collaboration inherent in healthcare settings.
By combining AI capabilities with human judgment, these systems enhance efficiency and accuracy while keeping clinicians firmly in the decision-making loop.
Challenges of On-Premise, Open-Source LLM Architecture in Healthcare

An on-premise, open-source LLM setup offers clear benefits for privacy, control, and compliance in healthcare, but it’s not without its hurdles.
Successful implementation depends on more than just the right technology; it requires an organization to have mature MLOps practices, strong data governance, and well-trained clinical staff.
In this section, we’ll explore the key technical and organizational challenges that hospitals and research institutions must address to deploy these systems safely and effectively.
How to Address the Limitations of “Frozen-in-Time” Knowledge in Offline Models?
Offline LLMs are inherently static, meaning their knowledge is limited to the data they were trained on. In a fast-moving field like healthcare, where new research, disease trends, and treatment guidelines emerge constantly, this can quickly become a problem.
A RAG pipeline helps overcome this limitation by grounding the model’s outputs in a separate, up-to-date knowledge base. However, the effectiveness of the system depends entirely on the freshness and quality of that knowledge.
To address this, organizations need to implement a robust data pipeline and governance framework that continuously updates the internal knowledge base. Without this ongoing effort, the system risks becoming outdated, and in clinical settings, outdated information could lead to inaccurate or even harmful guidance.
What Are the Computational and Expertise Demands of On-Premise Control?
Deploying on-premise LLMs is computationally demanding, requiring high-performance hardware, especially GPUs and large memory configurations. The size and complexity of these models can strain existing infrastructure, leading to high operational costs and potential performance bottlenecks if not carefully managed.
Beyond hardware, human expertise is a critical factor. Unlike turnkey cloud solutions, on-premise systems demand specialists in model fine-tuning, data engineering, and MLOps to develop, implement, and maintain the system. Organizations need to either hire or train teams capable of keeping the model accurate, secure, and up-to-date over time.
The combination of capital expenses for hardware and human capital costs for expertise can be a significant barrier, making careful planning and investment essential for successful deployment.
How Can Hallucination and Bias in LLMs Be Mitigated Through Rigorous Evaluation?
Generative AI models are inherently unpredictable. They can produce “hallucinations”, plausible but inaccurate statements, and may reflect biases present in their training data.
In healthcare, these errors pose a serious risk to patient safety.
Mitigating this risk requires a rigorous evaluation framework. For clinical applications, this goes beyond standard accuracy metrics and often involves LLM-as-a-judge approaches to assess the clinical correctness and quality of outputs.
Another challenge is inconsistent responses: the same query can yield different answers depending on minor changes in phrasing or the order of information.
These vulnerabilities mean that manual oversight and extensive testing are essential to ensure the system performs reliably and safely in a healthcare context.
Why Is Human Oversight Essential in Healthcare When AI Augments Clinicians?
No matter how powerful generative AI becomes, the human touch in medicine remains irreplaceable. The system outlined in this blueprint is not an autonomous agent; it’s a tool designed to augment clinicians, not replace them.
Challenges like hallucinations, inconsistent outputs, and the model’s inability to fully interpret complex clinical data make a human-in-the-loop approach a necessity, not an option.
To succeed, organizations must invest in practical training for healthcare professionals:
- Writing effective prompts to get accurate results
- Critically reviewing AI-generated outputs for correctness and bias
- Understanding the limitations of the system
A successful deployment depends on fostering a culture of confident, safe use, where clinicians feel empowered to leverage AI tools while relying on transparent safeguards to maintain patient safety and compliance.
Multi-Layered Recommendations for Implementing Offline AI in Healthcare

Building an offline-first, open-source AI framework is a strategic and technically feasible approach for healthcare organizations that value data sovereignty, security, and long-term control.
By leveraging a modular stack of open-source tools and a private RAG pipeline, this architecture directly addresses the security and compliance risks of commercial cloud-based solutions.
However, implementing such a system is complex and requires a multi-layered approach to planning, execution, and ongoing governance.
In the following section, we provide practical recommendations for organizations looking to adopt this approach successfully, balancing technical requirements with operational and human considerations.
Strategic Recommendations
- Prioritize a Total Cost of Ownership (TCO) Analysis: Before starting, organizations should perform a thorough TCO assessment. This includes not just capital expenditure on hardware, but also long-term operational costs for specialized talent in model development, maintenance, and data governance.
- Align with an Insourcing Philosophy: Building an on-premise system is a strategic decision to bring control of data and technology in-house. Success requires institutional buy-in and a long-term commitment to developing an internal center of excellence for AI and machine learning.
- Establish a Culture of Compliance: Security and privacy must be built into the organization’s DNA, not treated as an afterthought. Clear policies and a robust governance framework are essential to prevent shadow IT and ensure responsible, compliant use from day one.
Technical Recommendations
- Start with a Pilot on a Low-Risk Use Case: Implement the system in phases, beginning with a well-scoped pilot such as automated literature review or EHR note summarization. This allows the organization to validate the architecture before scaling to high-stakes applications like clinical decision support.
- Invest in Data Engineering: The performance of the RAG pipeline depends entirely on the quality of the knowledge base. Allocate significant resources to curating, cleaning, normalizing, and ingesting internal data into the local vector store to ensure accurate and reliable outputs.
- Build a Modular Pipeline: Treat architectural components as a layered ecosystem. Modular design allows individual components, such as the vector database or LLM, to be updated or replaced as new technologies emerge, keeping the system adaptable, scalable, and future-proof.
Operational & Governance Recommendations
- Implement a “Human-in-the-Loop” Model: For all clinical applications, human oversight is essential. The interface should empower clinicians with transparent, auditable, and traceable outputs, including a clear escalation path for any unexpected or concerning results.
- Provide Mandatory Training: Every user, from researchers to clinicians, needs practical, hands-on guidance on safe and effective system use. Training should cover the system’s capabilities, limitations, and best practices for prompt engineering and verifying AI outputs.
- Establish a Rigorous Evaluation Framework: Continuous monitoring is critical. Use a combination of automated checks and human-in-the-loop evaluations to ensure accuracy, reduce hallucinations, and minimize bias in AI-generated recommendations.
Final Thoughts

Offline, on-premise, open-source LLMs represent a powerful opportunity for healthcare organizations seeking control, privacy, and long-term flexibility. By combining modular tools, a private RAG pipeline, and a human-in-the-loop model, hospitals and research institutions can unlock the benefits of generative AI while maintaining strict compliance and safeguarding patient data.
Success requires more than technology; it demands strategic planning, robust data governance, ongoing training, and dedicated expertise. Organizations that take a layered, methodical approach can not only implement these systems safely but also transform clinical workflows, accelerate research, and enhance patient care.
Ultimately, the goal is clear: to create AI tools that augment human expertise, empower clinicians, and preserve trust, ensuring that innovation in healthcare is both effective and responsible.
Building a secure, offline, on-premise AI system is complex, but you don’t have to do it alone. Bitcot specializes in designing and implementing adherent, high-performance, and custom AI solutions for healthcare organizations.
Whether you’re looking to pilot a RAG system, streamline EHR analysis, or enhance clinical decision support, our team can guide you from strategy to deployment, ensuring privacy, control, and long-term scalability.
Connect with Bitcot today to start building the future of healthcare AI; secure, intelligent, and fully in your hands.











