You’ve already experimented with AI, but be honest, has it really delivered the results you imagined?
Every business today is racing to unlock AI’s potential, yet most are stuck in the same loop: decent outputs, inconsistent accuracy, and rising costs. The problem isn’t the AI model itself; it’s how you optimize it.
Think about it:
- Are your chatbots still answering with outdated information?
- Do your automation tools sound smart but miss the context?
- Are your teams spending weeks trying to teach the model what your business already knows?
You’re not alone. Whether you’re a CTO trying to scale AI infrastructure, a business owner seeking faster ROI, or a non-technical founder navigating endless jargon, you already know what’s holding you back – fragmented optimization strategies.
Here’s the truth: AI isn’t plug and play anymore.
To truly outperform, you must decide how your AI learns, reasons, and retrieves knowledge. That choice between Prompt Engineering, Fine-Tuning, and Retrieval-Augmented Generation (RAG) determines whether your model remains a clever assistant or becomes a competitive advantage.
But let’s be real. You’ve read about all these terms before. You know the theory.
So ask yourself, if you already know this, where are you now?
Still waiting for your AI to get smarter? Still struggling to explain why accuracy dipped again?
That’s the hidden cost of inaction.
Every month without the right optimization strategy means lost productivity, lower customer trust, and missed revenue opportunities.
The good news is that you can fix it quickly.
In this guide, you’ll learn exactly how each optimization path works, where it performs best, and how to combine them for maximum results.
When you’re ready to move from theory to real outcomes, Bitcot can help. Our team builds AI systems that are faster, smarter, and designed to deliver measurable business value, not just technical benchmarks.
What Is Prompt Engineering for AI Models?
Prompt engineering involves crafting specific instructions that guide language models toward desired outputs. This method requires no model modification or additional training – just strategic input design that maximizes response quality.
The technique relies on understanding how LLMs interpret instructions. Well-structured prompts include clear context, specific formatting requirements, role definitions, and examples of expected outputs. Advanced strategies incorporate chain-of-thought reasoning, few-shot learning examples, and systematic prompt templates.
Key Benefits of Prompt Engineering
Quick implementation stands out as the primary advantage. Teams can start seeing improvements immediately without infrastructure changes or computational overhead. Zero additional costs beyond standard API usage make this approach accessible for organizations of all sizes.
The flexibility factor cannot be overstated. Prompt modifications happen in real-time, allowing rapid experimentation and iteration. Testing different approaches takes minutes instead of hours or days required by other optimization methods.
For businesses exploring AI and automation solutions, prompt engineering serves as an ideal entry point. The low barrier to entry allows teams to demonstrate value quickly before committing to more complex implementations.
Limitations to Consider
Prompt engineering hits ceiling effects with complex tasks. When problems require specialized knowledge beyond the model’s training data, even expertly crafted prompts may fall short. Response consistency can vary since the underlying model remains unchanged.
Token limits present practical constraints. Lengthy prompts consume valuable context window space, leaving less room for actual task completion. This becomes particularly problematic when working with models that have smaller context windows.
What Is Fine-Tuning for Large Language Models?
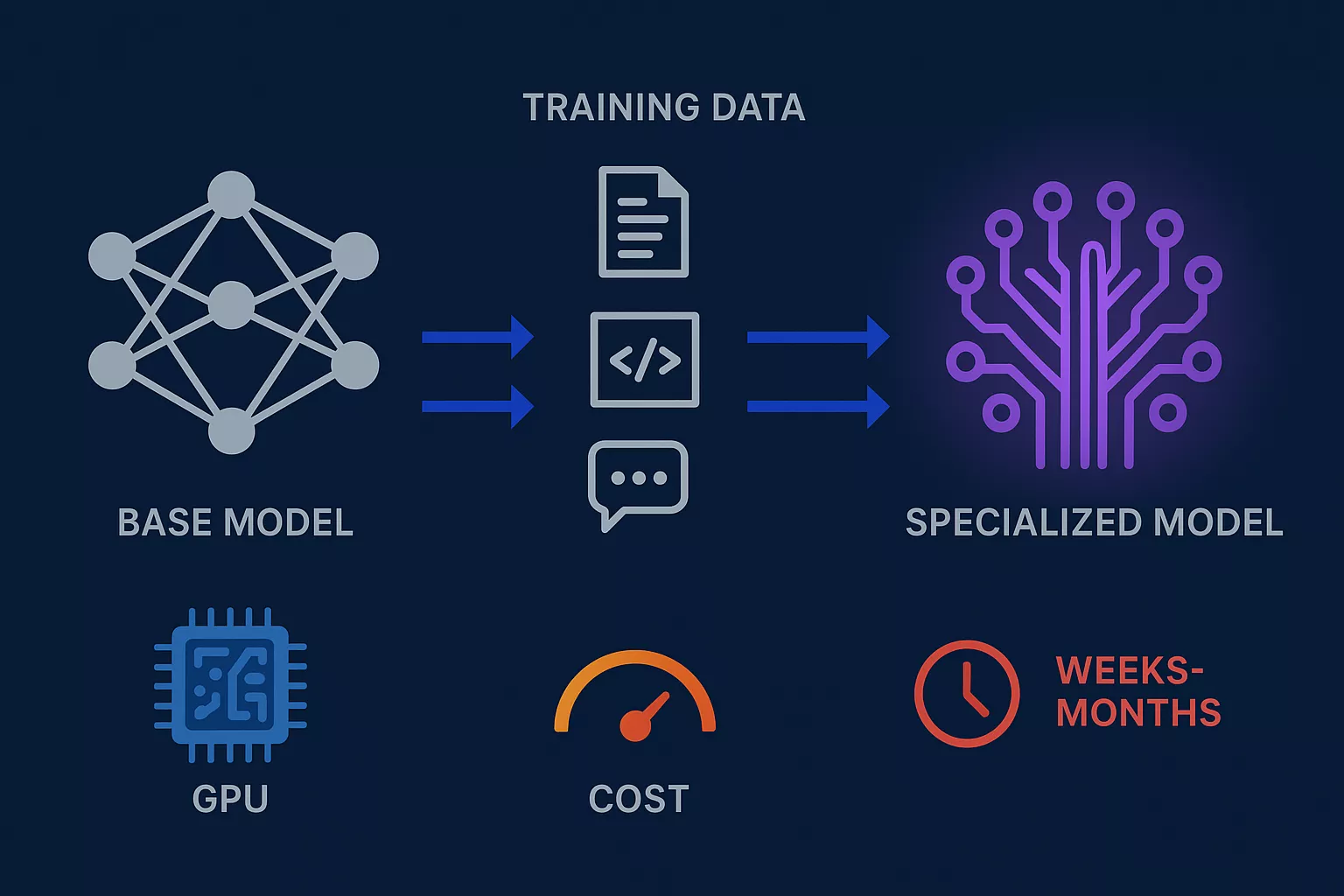
Fine-tuning involves retraining language models on specific datasets to specialize their capabilities. This process adjusts the model’s internal parameters, creating versions optimized for particular domains, writing styles, or task types.
The methodology requires curated training data, computational resources, and technical expertise. Organizations provide labeled examples demonstrating desired behaviors, then train the model through supervised learning processes that modify its neural network weights.
When Fine-Tuning Makes Sense
Domain-specific applications benefit tremendously from fine-tuning. Medical diagnosis systems, legal document analysis, and technical support automation all require specialized vocabulary and reasoning patterns that base models lack.
Behavioral customization represents another strong use case. Organizations wanting consistent tone, brand voice, or specific output formats across all interactions achieve this through fine-tuning. The model learns organizational preferences at a fundamental level.
Performance improvements for repetitive tasks justify fine-tuning investments. When the same types of queries occur thousands of times daily, optimizing the model specifically for those patterns delivers measurable efficiency gains. Many organizations partner with specialized AI development services to handle the technical complexity of fine-tuning implementations.
Fine-Tuning Challenges and Costs
Resource requirements create significant barriers. Training demands substantial computational power, often requiring GPU clusters and extended processing time. Smaller organizations may find these costs prohibitive.
Maintenance complexity increases over time. Models need retraining as business requirements evolve, data distributions shift, or newer base models become available. Each iteration requires similar resources to the initial training.
Data requirements present practical obstacles. Effective fine-tuning typically demands thousands of high-quality training examples. Creating, labeling, and validating these datasets requires significant human effort and domain expertise.
What Is Retrieval Augmented Generation (RAG)?
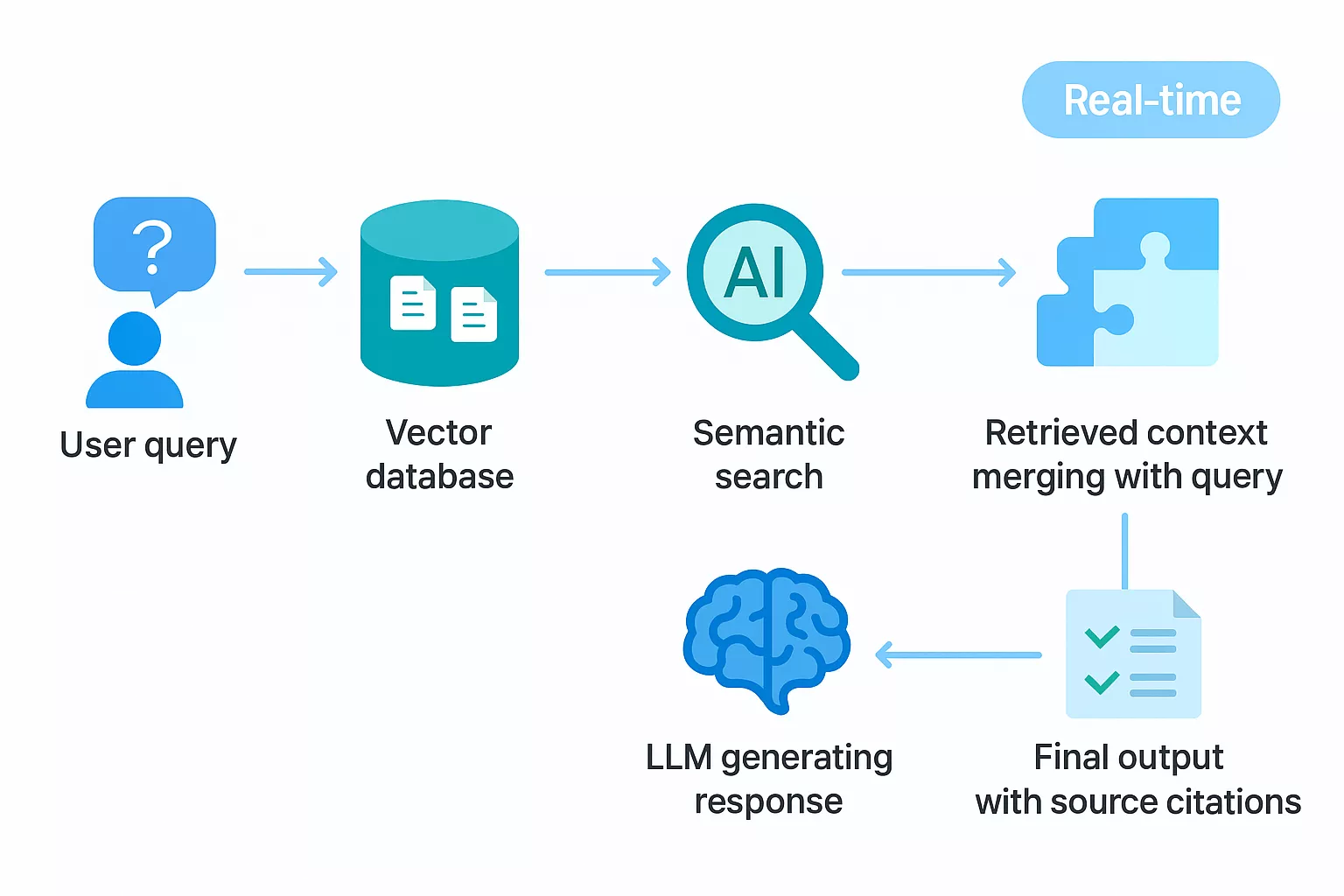
RAG combines language model capabilities with dynamic information retrieval systems. Instead of relying solely on training data, RAG-enabled models access external knowledge bases in real-time, retrieving relevant information before generating responses.
The architecture involves four distinct stages that work together seamlessly. Users submit queries that trigger information retrieval mechanisms. These systems search through connected databases using semantic search techniques that understand meaning rather than just matching keywords.
How RAG Systems Process Information
Query submission initializes the RAG pipeline. The system analyzes user intent and identifies relevant information requirements before accessing any external data sources.
Information retrieval mechanisms employ sophisticated algorithms that search internal databases, document repositories, and external knowledge sources. Vector databases organize information by semantic similarity, enabling intelligent matching between queries and relevant content.
Integration happens when retrieved data combines with the original query. This enriched prompt provides the language model with current, specific information that wasn’t part of its original training data.
Response generation leverages both retrieved facts and the model’s inherent language understanding. The combination produces contextually accurate answers grounded in real, verifiable information.
RAG Implementation Advantages
Knowledge freshness sets RAG apart from other approaches. Information updates happen at the data source level without requiring model retraining. Organizations maintain current AI responses simply by updating their knowledge bases.
Transparency and traceability improve significantly. RAG systems can cite sources, enabling users to verify information and understand reasoning chains. This builds trust and satisfies compliance requirements in regulated industries.
Cost efficiency emerges over time. While initial setup requires data engineering effort, ongoing operations avoid expensive retraining cycles. Organizations scale their knowledge bases without proportional increases in model maintenance costs.
RAG System Requirements
Data architecture complexity cannot be ignored. Building effective RAG systems requires robust data pipelines connecting various information sources to the language model. Data engineers must design, implement, and maintain these connections.
Semantic search infrastructure demands specialized tools. Vector databases, embedding models, and retrieval algorithms require setup and optimization. Organizations without existing search infrastructure face steeper learning curves.
Prompt engineering still matters. RAG systems need well-crafted prompts that help the model effectively utilize retrieved information. Simply providing data doesn’t guarantee optimal utilization without proper instruction design.
Comparing RAG vs Fine-Tuning vs Prompt Engineering
Different optimization methods serve different purposes. Choosing the right approach depends on specific requirements, available resources, and long-term strategic goals.
Quick Comparison Table
| Factor | Prompt Engineering | Fine-Tuning | RAG |
| Implementation Time | Minutes to hours | Weeks to months | Days to weeks |
| Initial Cost | Minimal (API fees only) | High (GPU, training) | Moderate (infrastructure) |
| Ongoing Maintenance | Low | High (retraining needed) | Moderate (data updates) |
| Technical Expertise | Low to moderate | High (ML expertise) | Moderate (data engineering) |
| Knowledge Updates | Manual prompt changes | Full retraining required | Update knowledge base |
| Performance Ceiling | Limited by base model | Highest for specific tasks | High with quality retrieval |
| Scalability | Easy across use cases | Challenging (multiple models) | Easy (expand knowledge base) |
| Best For | Quick wins, experimentation | Domain specialization | Current information needs |
Implementation Speed and Complexity
Prompt engineering wins for immediate deployment. No infrastructure changes or model modifications mean teams start optimizing today. Testing and refinement happen in real-time through simple text adjustments.
Fine-tuning requires substantial upfront investment. Data collection, model training, and validation processes span weeks or months before deployment. Organizations need machine learning expertise and computational infrastructure.
RAG systems fall between these extremes. Initial setup demands data engineering work and search infrastructure deployment. However, once operational, modifications happen quickly through knowledge base updates rather than model retraining.
Cost Considerations Across Methods
Prompt engineering maintains minimal costs. Standard API fees apply without additional training or infrastructure expenses. This makes it ideal for experimentation and organizations with limited budgets.
Fine-tuning involves significant capital expenditure. GPU hours, storage requirements, and ongoing maintenance create substantial recurring costs. Organizations must justify these expenses through measurable business value.
RAG systems require moderate initial investment in data infrastructure. Ongoing costs center on data storage and retrieval rather than model training. The cost structure favors organizations with existing data management capabilities.
Performance and Accuracy Factors
Prompt engineering delivers solid baseline performance but struggles with complex specialized tasks. Results depend entirely on the base model’s existing knowledge and capabilities.
Fine-tuning achieves superior performance for specific use cases. Models learn domain-specific patterns, terminology, and reasoning approaches that generalist models cannot match. This specialization comes at the cost of flexibility.
RAG excels at tasks requiring current, factual information. The ability to access updated knowledge bases ensures accuracy for time-sensitive queries. However, retrieval quality directly impacts response quality.
Scalability and Maintenance Implications
Prompt engineering scales effortlessly across use cases. Different prompts serve different purposes without infrastructure changes. However, managing prompt libraries and ensuring consistency across applications requires governance frameworks.
Fine-tuning scalability faces challenges. Each new domain or significant requirement change may necessitate separate model versions. Maintaining multiple fine-tuned models increases operational complexity exponentially.
RAG systems scale through knowledge base expansion. Adding new information sources or domains doesn’t require model retraining. This architectural advantage supports organizational growth and evolving information needs.
Combining Multiple Optimization Strategies
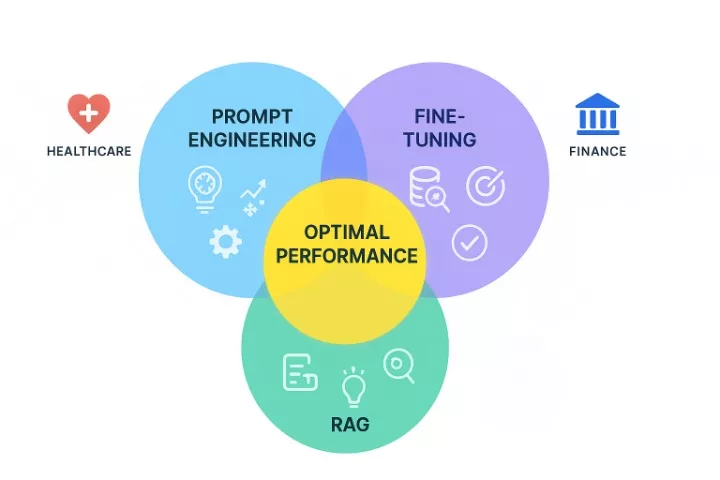
[IMAGE 6 – Hybrid Approach Venn Diagram] Prompt: Create an elegant Venn diagram with three overlapping circles. Circle 1 (Prompt Engineering) in translucent #10B5EE, Circle 2 (Fine-Tuning) in translucent #7B55E6, Circle 3 (RAG) in translucent #34AC9A. Center overlap area glowing in #FFDC5C with “Optimal Performance” text. Each circle contains 2-3 key benefit icons. Around the diagram, show industry examples: healthcare icon with #E11818, finance building with #2867A1, legal scales with #361B88. Clean white background with subtle geometric patterns in #EBEBEB. 1200x720px.
Organizations don’t need to choose just one approach. Combining methods often delivers superior results by leveraging complementary strengths.
Prompt Engineering Plus RAG
This combination provides immediate value. Well-crafted prompts guide how models utilize retrieved information, ensuring relevant data translates into useful responses. The synergy between retrieval quality and prompt design produces optimal outcomes.
Implementation remains relatively straightforward. Organizations build RAG infrastructure while simultaneously developing prompt templates that maximize retrieved data utilization. Both components improve independently and collectively.
Fine-Tuning Enhanced with RAG
Specialized models gain access to current information through RAG integration. A fine-tuned medical diagnosis model, for example, combines specialized medical reasoning with access to the latest research papers and clinical guidelines.
This approach requires significant resources but delivers unmatched performance for critical applications. Organizations with substantial AI investments and specialized domains benefit most from this comprehensive strategy.
All Three Methods Together
Enterprise-grade AI systems often employ all three techniques simultaneously. Base models receive fine-tuning for domain specialization, RAG provides current information access, and prompt engineering optimizes specific interactions.
The complexity justifies itself through superior results. Financial services firms, healthcare organizations, and legal tech companies frequently adopt this comprehensive approach for mission-critical applications.
How to Choose the Right AI Optimization Method
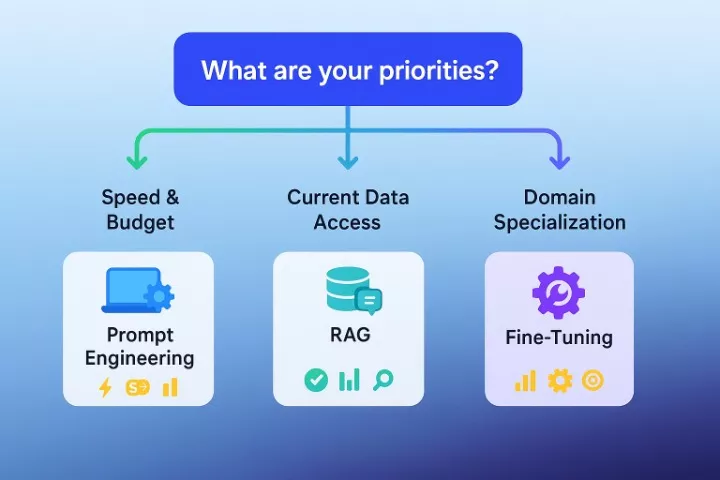
Strategic decision-making begins with clear requirement assessment. Organizations should evaluate their specific needs against each method’s strengths and limitations.
Decision Framework Table
| Your Requirement | Recommended Approach | Why |
| Need results within days | Prompt Engineering | Zero setup time, immediate testing |
| Require current/live data | RAG | Real-time knowledge base access |
| Domain-specific terminology | Fine-Tuning | Learns specialized vocabulary |
| Limited budget (<$10K) | Prompt Engineering | Minimal infrastructure costs |
| Consistent brand voice | Fine-Tuning | Behavioral customization |
Evaluating Your Use Case
Information freshness requirements point toward RAG. Applications needing current data – customer support with product updates, news analysis, or regulatory compliance – benefit from real-time information access.
Specialized domain knowledge suggests fine-tuning. Industries with unique terminology, reasoning patterns, or output requirements achieve better results through model specialization.
Budget and timeline constraints favor prompt engineering. Organizations wanting quick wins without major investments start here before potentially expanding to more sophisticated approaches.
Resource and Expertise Assessment
Technical capabilities matter significantly. Fine-tuning requires machine learning expertise, while RAG demands data engineering skills. Prompt engineering needs strong understanding of language model behavior but lower technical barriers.
Infrastructure availability influences decisions. Organizations with existing data lakes and search infrastructure deploy RAG more easily. Those with GPU access and ML operations experience pursue fine-tuning more readily.
Long-Term Strategic Considerations
Maintenance requirements extend beyond initial deployment. Fine-tuned models need retraining as requirements evolve. RAG systems require ongoing data quality management. Prompt engineering demands continuous refinement as models and use cases change.
Flexibility for future needs deserves consideration. RAG architectures adapt more easily to new information sources and domains. Fine-tuning creates specialized but less flexible solutions. Prompt engineering offers maximum flexibility but performance limitations.
Best Practices for Implementation Success
Successful AI optimization requires methodical approaches regardless of chosen methods.
Start with Clear Objectives
Define measurable success criteria before implementation. Specific metrics – response accuracy, user satisfaction scores, task completion rates – enable objective evaluation of different approaches.
Understanding baseline performance helps set realistic expectations. Test base models with standard prompts to establish comparison points for optimization efforts.
Iterate and Measure Continuously
Systematic testing reveals optimization opportunities. A/B testing different prompts, retrieval strategies, or fine-tuning approaches identifies what actually improves outcomes versus what sounds good theoretically.
User feedback provides invaluable insights. Real-world usage patterns often differ from expected behaviors, and continuous monitoring catches edge cases and optimization opportunities.
Build for Maintainability
Documentation prevents knowledge loss. Detailed records of prompt strategies, fine-tuning datasets, and RAG configurations enable team continuity and troubleshooting.
Version control applies to AI systems just like software code. Tracking prompt changes, model versions, and knowledge base updates enables rollback when problems arise.
Invest in Data Quality
Garbage in, garbage out applies universally. Fine-tuning data quality directly impacts model performance. RAG retrieval accuracy depends on well-organized, clean knowledge bases. Even prompt engineering benefits from accurate examples and context.
Data governance frameworks ensure consistency. Establishing standards for data labeling, knowledge base curation, and prompt templates maintains quality across teams and projects.
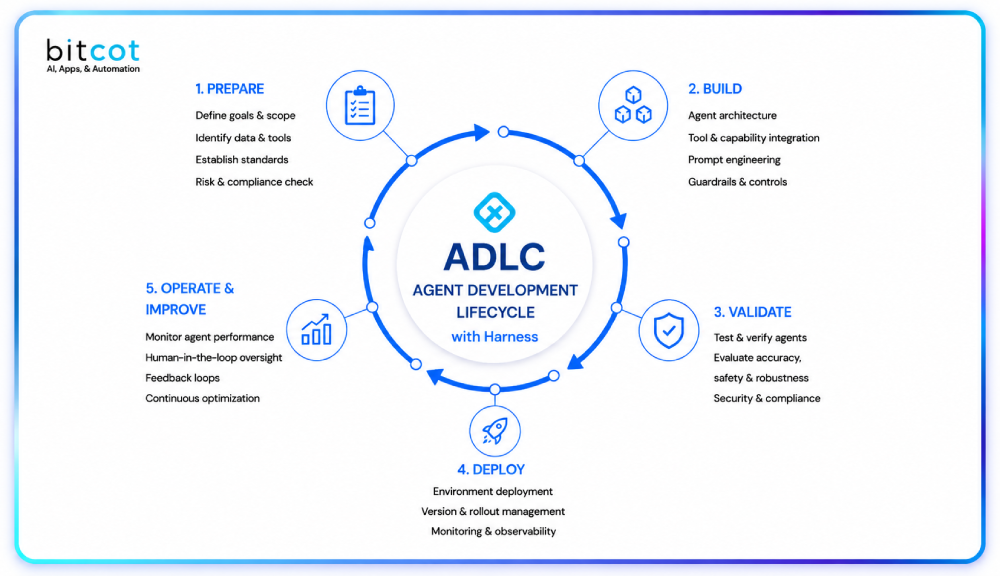
Implementing AI Agents with Optimized Models
Modern AI agent development combines these optimization strategies to create autonomous systems that handle complex workflows. AI agents leverage RAG for accessing current information, fine-tuning for domain expertise, and advanced prompting for task-specific interactions.
These intelligent agents can automate customer service, process documentation, manage scheduling, and perform data analysis – all while continuously learning and improving. Organizations implementing AI agents typically see significant reductions in manual workload and faster response times across multiple business functions.
Building effective AI agents requires understanding how to structure autonomous systems that combine multiple optimization techniques. The architecture must balance performance, cost, and maintainability while ensuring agents operate reliably within defined parameters.
Enhancing Customer Interactions Through Optimization
Customer-facing applications particularly benefit from proper AI optimization. Chatbot development leverages all three optimization methods to create conversational experiences that feel natural and helpful.
RAG enables chatbots to access product catalogs, knowledge bases, and customer history in real-time. Fine-tuning ensures brand voice consistency and industry-specific language understanding. Prompt engineering guides conversational flow and response formatting.
The result is AI-powered customer support that handles routine questions instantly, reduces wait times, and provides 24/7 availability. Organizations implementing optimized chatbots report higher customer satisfaction scores and reduced support costs.
Future Trends in AI Model Optimization
The AI optimization landscape continues evolving rapidly. Understanding emerging trends helps organizations plan long-term strategies.
Automated Optimization Tools
AI-assisted prompt engineering tools are emerging. These systems suggest prompt improvements, test variations automatically, and learn from successful patterns. The barrier to effective prompt engineering continues lowering.
Automated fine-tuning platforms simplify model specialization. Managed services handle infrastructure complexity, making fine-tuning accessible to organizations without deep ML expertise.
Hybrid Architectures
Next-generation systems blur lines between optimization methods. Models with built-in retrieval capabilities reduce architectural complexity while maintaining RAG benefits.
Multi-modal optimization combines text, image, and structured data. Organizations tackle increasingly complex use cases through integrated optimization strategies across different data types.
Enterprise AI Platforms
Integrated solutions bundle multiple optimization approaches. Enterprise platforms provide prompt engineering interfaces, fine-tuning capabilities, and RAG infrastructure in unified environments.
This consolidation reduces complexity for organizations deploying AI at scale. Single platforms handle multiple optimization methods with consistent interfaces and centralized management.
Streamlining Operations with AI Optimization
Beyond customer-facing applications, AI optimization transforms internal operations. Workflow automation services integrate optimized AI models to eliminate manual tasks, reduce errors, and accelerate business processes.
Optimized AI systems handle data entry, document processing, approval routing, and reporting automatically. RAG ensures access to current policies and procedures. Fine-tuning adapts systems to organizational workflows. Prompt engineering guides decision-making logic.
Organizations implementing AI-powered workflow automation report significant time savings, with employees freed from repetitive tasks to focus on strategic initiatives. The combination of optimization techniques ensures these automated workflows perform reliably and adapt to changing business needs.
Making Your AI Optimization Decision
The choice between RAG, fine-tuning, and prompt engineering depends entirely on specific circumstances. No universal best answer exists – only optimal choices for particular situations.
Organizations starting their AI journey benefit from prompt engineering’s low barrier to entry. This builds experience and demonstrates value before larger investments. As requirements grow more sophisticated, layering in RAG or fine-tuning addresses emerging needs.
Success ultimately comes from matching optimization methods to actual requirements rather than following trends or making technology-driven choices. Understanding each approach’s strengths, limitations, and resource requirements enables informed decisions that deliver measurable business value.
Working with an experienced AI automation agency like Bitcot accelerates implementation while reducing risks. With expertise across RAG systems, fine-tuning approaches, and advanced prompt engineering, specialized partners help organizations navigate complex decisions and deploy solutions faster. Bitcot’s track record of 500+ successful projects demonstrates their capability to deliver results across diverse industries and use cases.
The AI optimization landscape will continue evolving, but fundamental principles remain constant. Clear objectives, systematic measurement, continuous iteration, and appropriate resource allocation drive success regardless of specific technical approaches chosen.
Ready to implement AI optimization strategies for your business? Contact an AI development specialist to discuss RAG implementation, fine-tuning approaches, or prompt engineering strategies tailored to your specific needs.
Frequently Asked Questions (FAQs)
What is the difference between RAG and fine-tuning?
RAG retrieves information from external knowledge bases in real-time without modifying the model, while fine-tuning retrains the model’s parameters on specific datasets to specialize its capabilities. RAG is better for accessing current information and requires less computational resources, whereas fine-tuning excels at learning domain-specific patterns and behavioral customization but requires significant GPU resources and training time.
Can you combine RAG, fine-tuning, and prompt engineering together?
Yes, combining all three methods often delivers the best results for enterprise applications. Fine-tuning specializes the model for your domain, RAG provides access to current information, and prompt engineering optimizes specific interactions. Many organizations in healthcare, finance, and legal sectors use this comprehensive approach for mission-critical applications, though it requires more resources and technical expertise.
How much does it cost to implement each AI optimization method?
Prompt engineering has minimal costs (just API fees), making it ideal for budgets under $10K. Fine-tuning involves significant expenses including GPU hours ($1,000-$50,000+), data preparation, and ongoing retraining costs. RAG systems require moderate initial investment in data infrastructure ($5,000-$30,000) with lower ongoing maintenance costs compared to fine-tuning. The choice depends on your budget, timeline, and performance requirements.
Which optimization method is best for startups with limited resources?
Prompt engineering is the best starting point for startups with limited resources. It requires no infrastructure investment, delivers immediate results, and allows rapid experimentation. Once you validate your use case and secure more resources, you can layer in RAG for knowledge access or fine-tuning for specialized performance. This progressive approach minimizes risk while building AI capabilities.
How long does it take to implement each AI optimization approach?
Prompt engineering can be implemented in minutes to hours with immediate results. RAG systems typically take days to weeks depending on data infrastructure complexity. Fine-tuning requires weeks to months for data collection, training, and validation. If you need results quickly, start with prompt engineering while planning longer-term implementations of RAG or fine-tuning.
When should I use RAG instead of fine-tuning for my AI application?
Choose RAG when you need access to frequently updated information, multiple data sources, or source citations for compliance. RAG is ideal for customer support, documentation systems, and applications requiring current data. Choose fine-tuning when you need consistent domain-specific behavior, specialized terminology understanding, or optimized performance for repetitive tasks. Many applications benefit from combining both approaches.