Key Takeaways
- Build a React Native AI assistant that answers real order queries fast, cuts support cost, and scales reliably
- Why generic chatbots fail on real order queries and what does not
- The one architectural decision that eliminates AI hallucinations on order data
- Five engineering choices separating a PoC demo from a production AI assistant
- The six-week sprint roadmap from hypothesis to validated, live system
- What a production path looks like before any enterprise budget is committed
Your chatbot quotes the return policy. It cannot tell anyone where their order actually is.
Imagine this: a customer messages your support team at 10 PM on a Friday asking where their order is. Your chatbot fires back a cheerful reply about your return policy.
That gap between what your customer needs and what your automation delivers is costing more than you think. Not just in abandoned carts and chargeback disputes, but in the slow erosion of trust that happens every time a “smart” system proves it is not.
Most e-commerce brands know they need AI. What they do not know is that the tools they have bought to get there – the generic chatbot platforms, the FAQ bots, the per-conversation SaaS subscriptions – are architecturally incapable of doing the job. Intercom’s Fin AI charges $0.99 per resolved conversation. For a mid-sized brand handling 10,000 support queries a month, that is close to $9,900 in monthly recurring cost with no data ownership, no backend integration, and generic responses that fail the moment a customer asks anything about their actual order.
We built a working proof of concept to challenge that directly. In six focused weeks, we shipped a fully functional, context-aware AI e-commerce assistant integrated into a React Native mobile app, with zero vendor lock-in, zero LLM hallucinations on order data, and an architecture designed to hold up in production – not just demos.
This PoC handles the full customer support lifecycle: order tracking, payment receipts, cart queries, product discovery, and policy guidance, all in a single conversational interface across iOS and Android from one codebase.
Why Generic Chatbot Platforms Are Failing E-commerce Brands Right Now
The friction point in e-commerce support is not a lack of tools. It is the gap between “automated” and “actually helpful,” and the cost of that gap compounds every month you leave it unaddressed.
Across the United States, support teams are stretched between two failing approaches. Third-party chatbot platforms are cheap to launch but generic by design. They can quote your return policy word for word, but they cannot tell a customer that their order #12345 is stuck in a fulfillment center. They also come with per-conversation pricing that compounds fast.
Human support does not scale. Peak season exposes this every year. Customers wait hours for a status update that should take seconds. Cart abandonment climbs. Brand loyalty erodes. And chargeback rates rise when cancellation requests go unanswered.
The scale of this problem is larger than most brands realize. According to Tidio’s 2024 Customer Service Report, 62% of consumers would switch to a competitor after just one bad customer service experience – and chatbot failure is now among the top three reasons cited for that switching behavior. For high-volume e-commerce operations, that statistic is not an abstraction. It is a revenue line.
The hidden problem is context collapse. A customer asking “Where’s my stuff?” might need order status, payment confirmation, or delivery tracking. A generic bot routes them through menu clicks. A well-architected AI e-commerce chatbot answers instantly and accurately, every time. That is the problem we set out to solve – and the reason the architecture decision matters more than the tool choice.

The Roadmap to GenAI Success for SMEs: From Strategy to ROI
Asking an LLM to Retrieve Order Data Is the Wrong Architecture From Day One
Here is the insight most AI chatbot guides skip over: for transactional queries, asking a large language model to retrieve or reason about live order data is the wrong design from the start.
LLMs are exceptionally good at understanding intent, handling nuance, and generating natural-sounding responses. They are not reliable sources of truth for “Is order #987 shipped?” That question needs a SQL query, not a probability distribution.
The consequences of ignoring this are measurable. Research from Salesforce’s State of the Connected Customer report found that 68% of customers say they expect AI to understand their full history and context when handling a service request – yet fewer than 30% of deployed chatbots today are integrated with transactional backend systems. That gap is precisely where most AI support investments fail.
Our approach is a Hybrid AI Architecture built around a clean separation of concerns – the foundation of any effective conversational AI for e-commerce that handles real transactions.
For deterministic queries – order tracking, payment history, cart details, return flows – the backend runs exact database queries against PostgreSQL. The LLM never touches the data retrieval layer. The result is 100% accuracy on every ID-based query. Zero hallucinations on transactional data.
For general queries – product recommendations, comparison questions, policy nuance – we pass the request to OpenAI’s GPT-4o-mini via LangChain. The LLM handles the creative, conversational layer. The database handles the facts.
Context persistence bridges both. When a user asks “What about the payment for that?” the system knows what “that” refers to because it maintains a short-term memory cache with a 10-minute TTL. Natural conversation without the frustration of starting over.
This architectural separation – LLM for conversation, database for facts – is what separates a system that impresses in demos from one that survives production. Every dollar lost to chargebacks from a wrong cancellation confirmation is a direct cost of getting this wrong.
A Full-Stack Chatbot That Handles the Entire Customer Support Lifecycle
This is not a mockup or a prompt-engineered demo. We built a full-stack AI shopping assistant integrated into an existing e-commerce mobile application, covering the complete lifecycle of a customer support query.
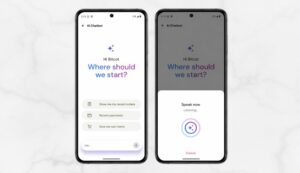
Order Management: Users ask for status, delivery dates, item lists, or initiate cancellations directly through chat.
Payment Tracking: Users request PDF receipts generated on demand, review payment history, or filter transactions by month.
Cart Insights: Users query total cost, check stock availability, identify the cheapest item, or verify delivery restrictions by pincode.
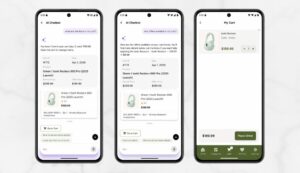
Product Discovery: Users ask for recommendations, compare products by specification, or filter by budget – exactly the kind of AI-powered product recommendation system modern customers expect.
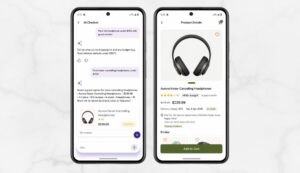
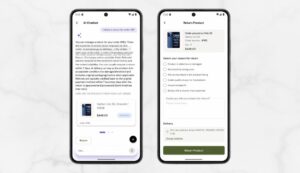
Policy Guidance: Instant answers on refund, return, and payment policies with no menu routing required.
According to Shopify, WISMO queries (“Where is my order?”) account for 30 to 40% of total support volume during normal periods and climb to 50% or higher during peak season. Resolving that category alone through automation fundamentally changes the economics of a support team.
The Five Engineering Decisions That Separate a PoC From Production AI
The difference between a chatbot that sounds impressive and one that holds up in production comes down to specific engineering choices. These five decisions drove the performance results we validated at the end of the sprint cycle.
Deterministic Order Tracking
The system detects Order IDs and Payment IDs in the user’s message using regex, extracts them immediately, and runs a SQL query against PostgreSQL. The LLM is never involved in this retrieval path. When a user types “Where is order #987?” the backend fetches exact shipping data and responds with precise delivery information. No guessing. No interpretation errors. 100% accuracy on every ID-based query.
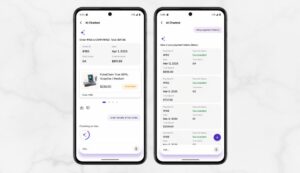
Intelligent Context Caching
A short-term in-memory cache with a 10-minute TTL preserves conversation state across turns. If a user asks “Show my last order” and then “Show the receipt,” the system resolves “the receipt” to the order already in context – no repetition required. This also dramatically reduces LLM token consumption per session, which translates directly to lower operating costs at scale.
Secure, On-Demand Receipt Generation
When a user requests a receipt, the backend generates a structured PDF using pdfkit, saves it temporarily, and issues a signed token that expires in 15 minutes. The user receives a download link in chat. The file never persists on the device. Financial documents are available immediately without permanently storing sensitive data anywhere they should not be.
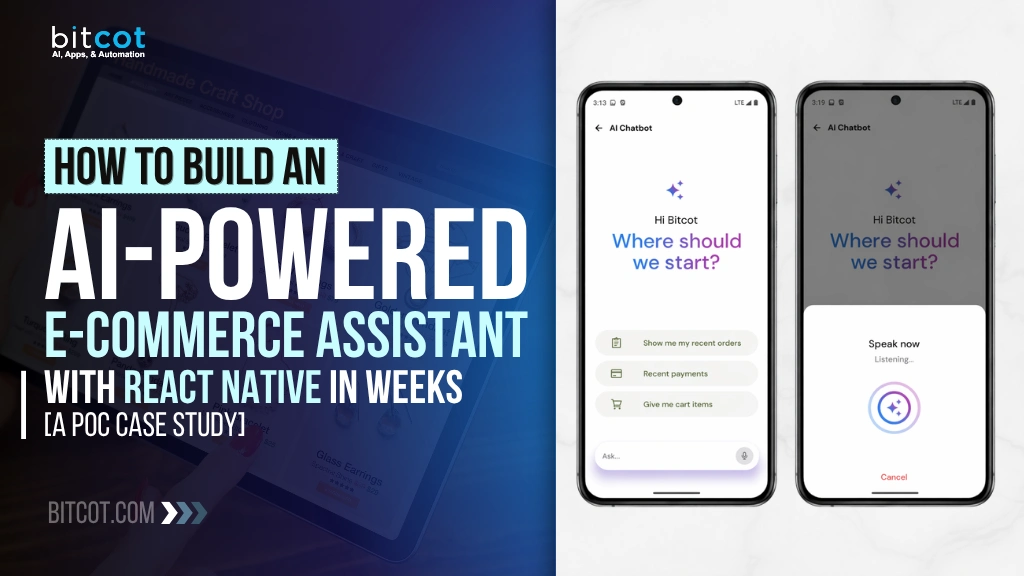
Voice-First Interaction via Speech-to-Text
The React Native app integrates a voice service that listens for 5 to 10 seconds, transcribes speech to text, and sends it to the chatbot backend. A user driving home taps the mic, says “Cancel my third order,” and receives a confirmation. Typing friction is removed. Accessibility improves across the full user base without a separate app or feature gate.
Privacy-First Data Redaction Before Every LLM Call
Before any user message reaches OpenAI, a regex-based redaction engine scans for and masks sensitive data – credit card numbers, CVV codes, passwords, and addresses. The LLM only ever sees intent and generic metadata. Raw user secrets never reach an external API. Even in a worst-case scenario involving an LLM provider breach, the exposure surface is near zero.
The table below summarizes each feature alongside its core outcome:
| Feature | Mechanism | Key Outcome |
| Deterministic Order Tracking | Regex ID detection + direct PostgreSQL query | 100% accuracy, zero hallucinations on transaction data |
| Intelligent Context Caching | In-memory cache, 10-minute TTL | Natural multi-turn conversation, lower token cost |
| On-Demand Receipt Generation | pdfkit + signed expiring download token | Immediate document access, no persistent sensitive file storage |
| Voice Input via STT | React Native native audio integration | Mobile-first accessibility, zero typing friction |
| PII Redaction Engine | Regex scan before every LLM call | Data privacy enforced by default, safe for production |
Each decision carries a deliberate trade-off. The deterministic handler requires its own routing logic per intent type. That is deliberate engineering work. But the reliability it produces is non-negotiable for any application where a wrong answer costs money.
Every Technology in the Stack and the Reasoning Behind Each Selection
Selecting the right stack was a decision about two things: response latency and data security. Every tool had to earn its place against both criteria, from React Native AI integration on the frontend to the backend pipeline.
Frontend – React Native 0.81.5 with Expo: Delivers a native mobile feel for iOS and Android from a single codebase. The react-native-gifted-chat library handles the chat UI, and native audio playback supports text-to-speech replies without requiring a third-party audio SDK.
Backend – Node.js with Express: Orchestrates the full pipeline between the database, the LLM, and the mobile client. Its event-driven model handles concurrent requests efficiently without thread blocking, which matters when multiple users are hitting the same endpoints during peak traffic.
LLM and Orchestration – LangChain with GPT-4o-mini: LangChain manages prompt templates and chain logic. GPT-4o-mini provides fast, cost-efficient responses for general queries. At $0.15 per million input tokens and $0.60 per million output tokens, this combination keeps LLM response latency under two seconds while keeping per-query costs at fractions of a cent.
Database and ORM – PostgreSQL with Prisma: Stores conversation history in the ai_prompt_responses table for analytics and context resumption across sessions. PostgreSQL Row Level Security isolates each user’s chat history at the database layer.
Frontend State – Zustand: Manages the global session cache, ensuring chat history persists through app refresh without requiring a full network round-trip to re-establish context.
Audio Pipeline – OpenAI TTS with Cloudinary: Converts text replies to natural-sounding MP3 audio. Cloudinary hosts the files for low-latency streaming to the mobile client.
Three Real Engineering Problems We Hit Mid-Build and How We Resolved Them
No architecture survives contact with real user behavior without hitting hard problems. These three required genuine engineering work and contain decisions that affect any team building in this space.
Resolving Ambiguous Natural Language Requests: SQL queries require IDs. Users say “the second one” or “the expensive one.” We built an Ordinal Resolver that maintains a list of the user’s last five orders. When a user says “the second order,” the system maps that ordinal to array index 1, extracts the ID, and queries it directly.
Generating Receipts Across Multiple Payment Gateways: Payment data arrives in different shapes depending on the gateway. Stripe, Razorpay, and manual entries each follow a different schema. We built a unified PaymentSummary mapper that normalizes data from every source into a single schema before it reaches the PDF generator.
Scroll Position Conflicts During Audio Playback on Mobile: When the AI responds with audio and a new message arrives, GiftedChat’s default behavior auto-scrolls the user to the bottom, interrupting active audio playback mid-sentence. We resolved this with a Scroll-to-Bottom Floating Action Button that only triggers if the user is already at the bottom.
Important Note: Ambiguous references like “the expensive one” still represent an edge case this resolver does not fully handle when price context is unavailable in session memory. Any team building in this space should scope disambiguation logic early and test it against real usage patterns – not just happy-path inputs – before production launch.
How We Shipped a Working AI Assistant in Six Focused Sprints
Time-boxing was an intentional architectural constraint, not just project management. Every sprint had a defined output and a done criteria tied to a functional milestone – not a percentage estimate. The goal was to prove the architecture, not pad a timeline.
| Sprint | Focus Area | Key Deliverable |
| Week 1 | Backend Foundation | Node.js routes, Prisma schema, OpenAI client integration, core Intent Router |
| Week 2 | Order and Payment Modules | Deterministic order and payment logic, on-demand PDF receipt generator |
| Week 3 | Frontend Chat UI | GiftedChat integration, custom Data Card renderer, Suggestion Chips |
| Week 4 | Context and Product Modules | In-memory context cache, Product Discovery with LLM reranking |
| Week 5 | Audio and Polish | OpenAI TTS integration, Cloudinary upload pipeline, Speech-to-Text voice modal |
| Week 6 | Testing and Security Audit | PII redaction testing, load testing, Ordinal Resolver edge case coverage |
Every sprint had a concrete deliverable the product team could evaluate and test. That approach – shipping working functionality weekly rather than iterating on a single component – is what kept the overall system coherent and allowed security and performance concerns to be addressed in the final sprint rather than retrofitted later.
The Validation Numbers That Proved the Hybrid Architecture Actually Holds Up
Validation was not a checkbox. It was the specific test of whether the architectural decisions made in week one actually delivered what they promised under real conditions.
Response Speed: Deterministic queries – order status and payment history – resolve in under 500ms. LLM fallback queries resolve in 1.5 to 2 seconds. PDF receipt generation completes in under 1.5 seconds.
Accuracy: 100% accuracy across all ID-based queries. Zero hallucinations on transactional data. Intent classification reached 94% accuracy after regex pattern training.
Stability: Concurrent requests for the same user’s history produced no cache corruption. Memory usage held below 120MB even when loading large conversation history logs during load testing.
One outcome exceeded projections: the context cache performed better than expected in real usage. Users rarely repeated themselves across turns, which sharply reduced the number of tokens sent to the LLM per session. That directly cuts operating costs at scale without any additional optimization work.
Those performance numbers are consistent with what the broader market is finding. According to McKinsey’s 2025 State of AI report, organizations that deploy AI in customer-facing workflows with a clearly defined human-in-the-loop architecture see 35% higher customer satisfaction scores compared to those running fully autonomous AI systems without handoff logic. Our hybrid design – deterministic for facts, LLM for conversation – is precisely that kind of bounded deployment.
What This Costs to Build, What It Displaces, and How Fast You Break Even
The business case is the actual reason this PoC exists. Let’s be direct about the numbers.
Building a focused PoC of this scope typically requires an investment of $20,000 to $35,000. For teams pursuing fast AI chatbot development for startups or mid-market brands, this PoC model is the right starting point. Hardening it for enterprise production – multi-lingual support, CRM integration, full CI/CD pipeline, human handoff flows – brings the total to $70,000 to $120,000.
Compare that to the ongoing cost of the alternative. Intercom’s Fin AI charges $0.99 per resolved conversation, with a 50-resolution monthly minimum. For a brand handling 10,000 support queries per month, that is approximately $9,900 in monthly recurring cost, with no data ownership, limited backend integration, and responses that fail on any query requiring real order context.
With an in-house solution, cost scales with actual usage. GPT-4o-mini is priced at $0.15 per million input tokens and $0.60 per million output tokens. In a well-architected hybrid system where most transactional queries are handled deterministically, LLM token consumption stays low by design. The payback period for a mid-sized e-commerce brand typically falls under six months.
More importantly, the PoC phase protects against the worst-case scenario: committing to a $120,000 production build only to discover the AI does not understand your specific inventory logic. The PoC eliminates that risk with a fraction of the investment and a live demo your product team can evaluate and stress-test before a dollar of production budget is approved.
What Actually Shifts in Your Operation When This Goes Live
Deployment creates measurable outcomes across four dimensions that map directly to revenue and cost lines. An AI customer support solution at this level of architectural rigor affects each of these dimensions in measurable ways.
Support Cost Reduction: According to Shopify, WISMO queries account for 30 to 40% of total support volume. Resolving that category through automation cuts support operational costs by 30 to 50% for most operations – a direct reduction in agent hours for the single highest-volume ticket category.
Conversion Rate Improvement: Answering product questions instantly in chat shortens time-to-purchase. Fewer drop-offs at the product consideration stage means more conversions from the same traffic without additional spend.
Chargeback and Dispute Prevention: A proactive cancellation flow through chat prevents customers from filing chargebacks when they cannot reach a human agent quickly enough. Dispute fees and processing costs are avoided before they are incurred.
Competitive Differentiation: A voice-enabled assistant that generates real-time receipts, tracks live order status, and surfaces product recommendations is a meaningful differentiator against competitors still routing customers through static FAQ pages and email queues.
The Roadmap From a Validated PoC to a Production-Ready AI Assistant
The six-week PoC is fully functional. Moving to enterprise production requires a defined scaling roadmap, and most of the groundwork is already laid.
Feedback Loop and Fine-Tuning: The Like/Dislike feedback mechanism is already built into the UI. In production, that signal feeds a fine-tuning pipeline to continuously improve intent classification without manual prompt engineering cycles.
Human Handoff Logic: The current retry logic needs to evolve into a full Agent Handoff capability – automatically transferring the conversation to a human agent when the AI’s confidence score falls below a defined threshold. That handoff logic is scoped for the first production phase.
Observability Tools: LangSmith or LangFuse need to be deployed to monitor token usage, track hallucination rates by intent category, and alert on classification degradation before it reaches customers.
GDPR and CCPA Compliance: Brands operating in US consumer markets must plan for compliance before full production launch. The deleteAllHistory endpoint is already built into this PoC, which gives the compliance team a working technical foundation rather than a retrofit problem to solve after launch.
The PoC does not just prove the concept. It front-loads the hardest architectural decisions so the path to production is a defined engineering exercise, not a second round of discovery.
How Bitcot Helps Teams Build AI-Powered E-commerce Assistants That Actually Work
Executing a secure, transaction-aware AI chatbot for e-commerce requires more than access to an API key. Our senior engineering teams bring the architectural discipline to know which layers of the system should never touch an LLM, the database engineering to enforce Row Level Security for per-user data isolation, and the mobile development rigor to ship a native-quality experience on both iOS and Android from a single codebase.
Here is what our approach to an engagement like this looks like in practice:
- Architecture-first discovery – we validate your support flow architecture and integration complexity before any code is written
- Hybrid AI architecture design – we define the deterministic boundary upfront, so the LLM is never trusted with facts it should not have
- Senior-only engineering execution – our engineers, designers, and PMs are all senior level; no junior handoffs on production-track work
- React Native development for iOS and Android from a single codebase, with native audio, voice input, and accessibility built in from sprint one
- eCommerce platform integration – our service modules are designed as API wrappers from the start, so Shopify, Magento, NetSuite, or any custom ERP can slot in without rebuilding the conversation layer
- Post-launch support and observability – we deploy monitoring tooling and are available as a long-term engineering partner, not just a project vendor
We delivered this PoC with strict adherence to deterministic fallback architectures and applied PostgreSQL Row Level Security to ensure no user’s conversation history is ever accessible to another. We built every feature against a security audit standard, not after one. See how we approach these builds.
Why This PoC Changes the Math on AI Customer Support for Growing Brands
This project challenges a belief that has quietly held back a lot of companies: that intelligent, transaction-aware AI support requires a large data science team, a specialized ML platform, or a budget only available to the largest retailers.
It does not.
The stack in this PoC – React Native, Node.js, OpenAI, PostgreSQL – is accessible to any competent engineering team. The architectural pattern – deterministic data access combined with LLM-powered conversation – is reproducible across any industry where AI needs to discuss real business data accurately and safely.
For founders and operators across America who have been watching larger competitors deploy AI-powered shopping experiences, this is the practical proof that the gap is closer than it appears. The question is no longer whether to build it. The question is whether to build it with the architectural discipline that makes it trustworthy – or to default to a generic tool that answers every question except the one your customer is actually asking.
If you are ready to move from evaluation to proof, talk to our team. We will map out exactly what your AI assistant needs to do and what it will take to build it so you are not replacing it in six months.
Frequently Asked Questions (FAQs)
Is OpenAI secure enough for handling real customer order and payment data?
Yes, when the architecture is designed correctly. Our system runs a redaction engine on every user message before it reaches OpenAI. PII – names, addresses, credit card numbers, passwords – is replaced with masked tokens. The LLM only sees intent and generic metadata. Actual order and payment data is handled entirely by deterministic Node.js code querying the database directly. Even in a worst-case provider breach scenario, raw user data is not exposed.
Can this chatbot integrate with an existing ERP or inventory system?
Yes. The backend service modules are designed as wrappers around API calls. The Prisma database queries can be replaced with calls to any REST or GraphQL inventory or ERP API without touching the conversation layer or intent routing logic. We have built similar integrations for eCommerce platforms and enterprise systems across retail, logistics, and marketplace verticals.
How long does it take to go from a PoC to a production-ready assistant?
A functional PoC takes four to six weeks. Transitioning to a production-hardened system with full CI/CD, human handoff, multi-lingual support, and CRM integration typically adds eight to ten weeks. The PoC validates the architecture and business fit before that full investment is committed – which is the point.
What does it cost to maintain once deployed?
Ongoing costs are primarily OpenAI API usage. GPT-4o-mini is priced at $0.15 per million input tokens and $0.60 per million output tokens. Because the hybrid architecture handles most transactional queries deterministically without LLM calls, token consumption stays well below what a purely LLM-based chatbot would generate. There are no per-seat or per-conversation license fees.
Can the chatbot handle returns and refunds automatically?
Yes. The Refund Intent module detects return requests, interfaces with your logistics provider API to generate return labels, and guides users through the full return flow via action buttons in the chat UI. Cancellations and returns are handled as structured, deterministic flows with confirmation at each step – never left to the LLM to improvise.
What compliance considerations apply to an AI chatbot handling customer data?
For US-based brands, CCPA compliance requires the ability to delete user data on request – the deleteAllHistory endpoint in this PoC addresses that directly. PCI-DSS guidelines require that cardholder data never reach external systems unmasked – our redaction layer enforces that. For brands handling health-adjacent data, architecture decisions around data isolation and audit logging should be made upfront, not retrofitted. We build with these requirements in mind from sprint one.
What happens when the AI does not know how to answer a query?
When the intent classifier cannot confidently categorize a message, the system routes it to the general LLM handler with a conservative prompt. If confidence falls below a defined threshold – planned for production implementation – the conversation routes automatically to a human agent with full context preserved. The user is never left in a dead end.











