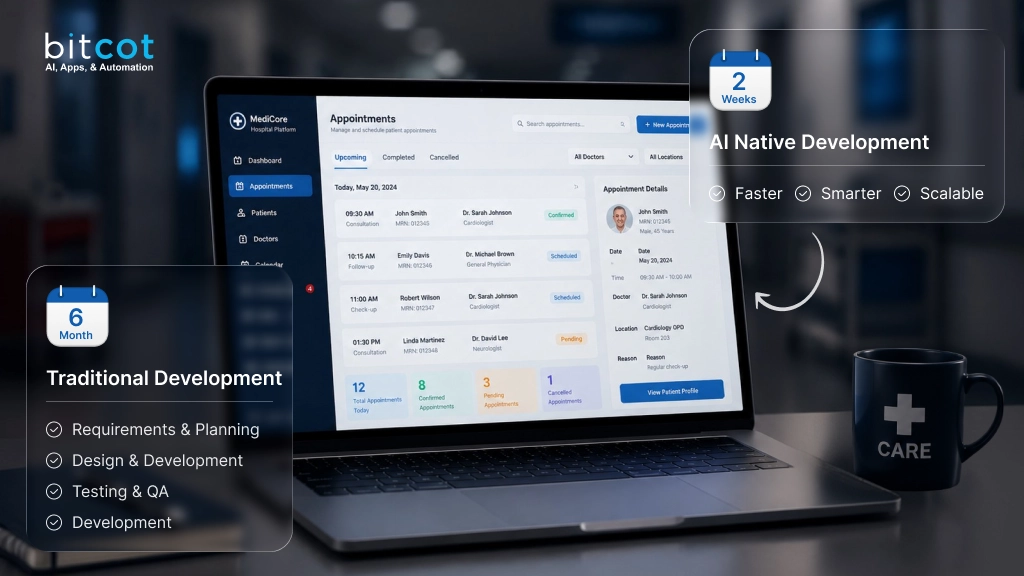
Key Takeaways
- Poor EHR navigation quietly consumes up to 35% of a clinical shift.
- A focused PoC answers integration questions weeks before production.
- Decoupling the frontend and backend keeps clinical AI stable inside legacy EMR environments.
- AI patient context awareness eliminates manual data entry and reduces the risk of errors.
- The simpler the architecture, the better the performance – proven by 100% load reliability.
What if your clinical team could stop navigating menus to find patient information and simply ask for it – and receive an accurate, patient-specific answer in under five seconds, every time?
If you manage a clinic, operate a healthcare platform, or build software that clinicians rely on daily, you already know this gap. Staff navigate systems that were never designed for the speed that modern patient care demands.
Electronic health records were built to store patient data accurately – not to surface it fast. As patient volumes grow, the gap between what EMR systems can do and what teams need has become a measurable daily operational cost.
According to Fortune Business Insights, the global market for AI chatbots in healthcare was valued at nearly $2 billion in 2025 and is growing at a 23% annual rate – a pace driven almost entirely by US healthcare organizations demanding faster clinical workflows and lower administrative burden.
We built a direct response to this problem: an AI assistant for healthcare app environments that lives inside OpenEMR and gives clinical staff accurate, patient-specific answers in plain English.
What follows documents the full build – what worked, what failed in the first attempt, and what every healthcare team should understand before pursuing OpenEMR AI integration at any scale.

How Legacy EMR Systems Create a Hidden Productivity Tax on Clinical Staff
OpenEMR Was Built for Data Storage, Not Clinical Speed
Healthcare platforms like OpenEMR were designed with one primary goal: store and manage critical patient data reliably. Usability was a secondary consideration – not an architectural priority from the start.
Information lives scattered across separate modules. Staff must memorize exact navigation paths. Even straightforward queries demand multiple clicks and manual cross-referencing across different sections of the system.
These are not edge cases. They are the daily reality inside most clinical environments, and they are exactly the pain points our EHR and EMR software development work is built to address.
What Slow Information Access Costs Clinics Every Single Day
Every minute spent clicking through menus is a minute not spent on patient care. A 2022 study published in
JAMIA found that nurses spend up to 35% of each shift on documentation and system navigation – a figure largely driven by poor EMR usability rather than documentation complexity itself.
Multiply that across an entire clinical team, every shift, every week. The cumulative loss of direct care time becomes a significant quality-of-care issue that no amount of additional training can resolve.
More Training Is Not the Answer – Here Is What Actually Reduces EMR Friction
Most healthcare organizations respond to usability gaps with more training sessions, better documentation, and expanded IT support channels. These approaches treat the symptom. They do not fix the underlying system.
The Compounding Operational Cost of Manual Clinical Workflows
Every new hire requires weeks of system onboarding before they are fully productive. Every workflow update creates confusion and errors across experienced staff who have memorized the old way. Every complex query becomes a guessing game with no reliable shortcut.
The real cost is not just time – it is the accumulating burden on clinical teams who are already operating at or beyond comfortable capacity on a daily basis.
What Clinical Teams Actually Need From Their Systems
Staff do not need more documentation. They need to ask a question and get a clear, reliable answer immediately. They need a system that responds like a knowledgeable colleague – not a filing cabinet that requires a user guide to navigate effectively.
That is the gap that clinical workflow automation software AI is designed to close: not by replacing human clinical judgment, but by removing the friction that delays it at every step of the shift.
The Question That Shaped Every Technical Decision We Made
Can we build a lightweight AI chatbot inside OpenEMR that allows healthcare staff to ask questions in plain English and receive accurate, patient-specific answers instantly – without disrupting a single existing workflow?
That was our starting hypothesis. Not a vague AI strategy, but a specific, testable question with a clear and measurable success condition. Answering it shaped every technical decision that followed throughout the build.
The best AI does not feel like an add-on. It feels like the system always worked this way. That was our design standard from the first line of code.
A Different Entry Point Into Healthcare AI
When teams approach AI implementation in healthcare systems, they typically begin by asking what AI is capable of. We started from a different angle: how should users ideally interact with this system in the first place?
That shift – from AI capability to actual user workflow – changed everything about how we built, tested, and iterated. It is also the reason the final integration held up where our first technical attempt failed completely.
Skipping Validation Is How Healthcare AI Projects Stall – Here Is Our PoC Approach
Before building anything at scale, we needed to answer one foundational question: will an AI chatbot actually integrate and function inside a live OpenEMR environment?
A Proof of Concept gave us a structured, low-risk way to find out. Rather than committing to full-scale development, we built just enough to test integration feasibility and identify technical constraints before they became expensive problems deep in production.
What a Proof of Concept Tells You That Planning Cannot
A PoC is not about building the perfect product. It is about learning what works, what breaks, and what needs to change before committing serious resources. In embedded healthcare environments, that early validation is not optional – it is the difference between a project that ships and one that stalls for months with no clear path forward.
The Four Questions We Needed Answered Before Building Anything at Scale
- Is it technically feasible to embed a chat interface inside OpenEMR without destabilizing the host system?
- Does the AI respond accurately using real, structured patient data rather than generic outputs?
- Are there framework conflicts that would block a stable, reliable production build?
- What is the minimum viable architecture needed for consistent, near-real-time performance?
The PoC answered all four – and one answer changed our technical direction entirely before we had invested resources in the wrong approach.
How Clinical Staff Use the OpenEMR AI Chatbot – Step by Step
From Concept to Lightweight Integration – What the Chatbot Actually Does
Rather than forcing tools to fit where they were not designed to go, we stepped back and asked what the chatbot genuinely needed to do. Our approach to OpenEMR customization services always starts there: with the real clinical use case, not the available toolkit.
The answer was clear. Show a chat window inside OpenEMR. Let users type questions. Send those questions to an AI backend. Return a patient-specific answer to the chat window. No server-side rendering. No over-engineered framework. A lightweight interface powered by a smart, decoupled backend.
A Step-by-Step Look at the Chatbot Inside OpenEMR
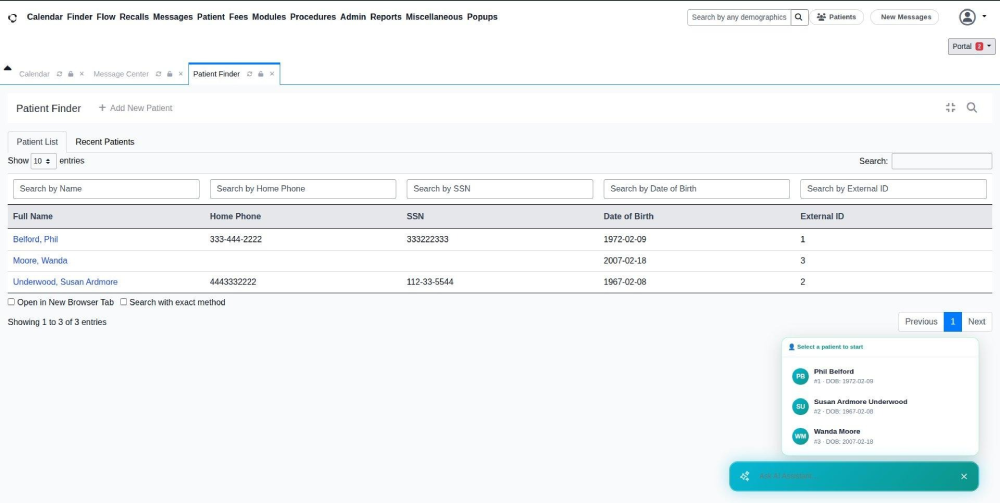
Step 1 – Selecting the Right Patient to Work With
When a staff member opens the chatbot, they see a list of current patients. One click selects the patient and the AI immediately loads that patient’s full medical context. No typing, no ID lookup, no risk of pulling the wrong person’s records during a busy clinic period.
Step 2 – The Chat Window Opens and Is Ready Immediately
Once a patient is selected, the AI confirms it has loaded that patient’s records. Quick-action buttons appear at the bottom: Summarize Chart, Predict Risk, List Encounters. Users can act immediately without typing a single word.
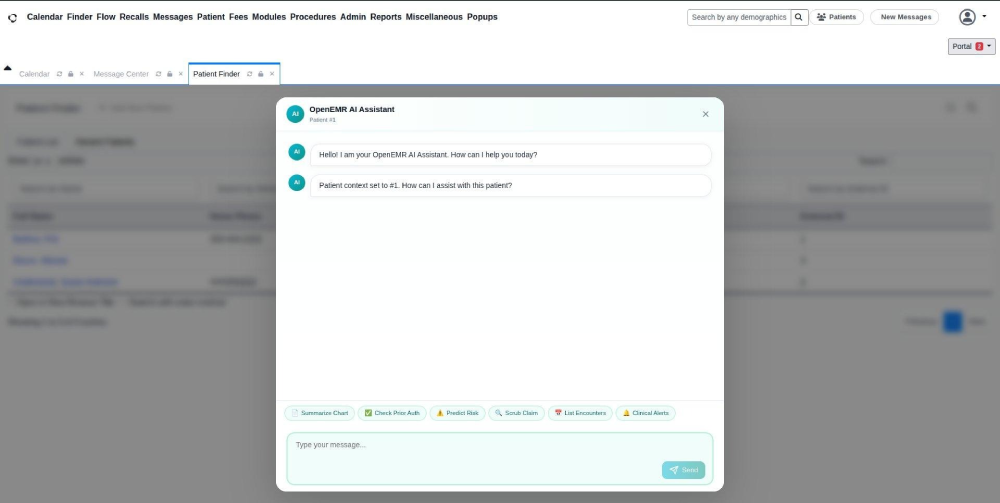
Step 3 – Asking a Question in Plain English
The user types: ‘What is the readmission risk for this patient?’ A brief thinking indicator appears while the AI processes the patient’s full medical history in the background and prepares a structured, context-aware response.
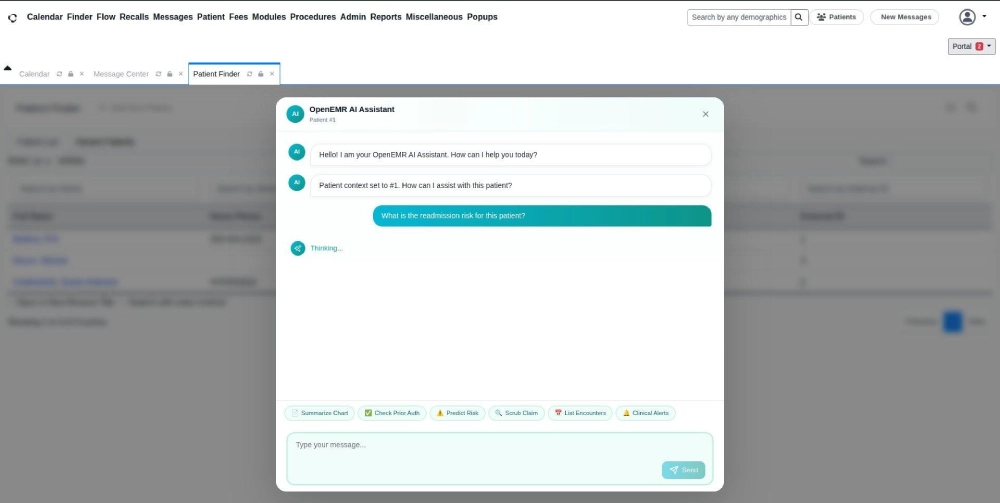
Step 4 – A Structured, Actionable Answer Based on Real Records
The AI responds in plain English. This patient carries a 42% readmission risk within 30 days, classified as medium risk, based on multiple hospitalizations, worsening blood glucose, elevated blood pressure, and declining kidney function – all derived directly from actual patient records in the system.
A physician or nurse reads this in seconds and knows exactly what requires clinical attention – without spending ten minutes pulling raw notes from different modules across the system.
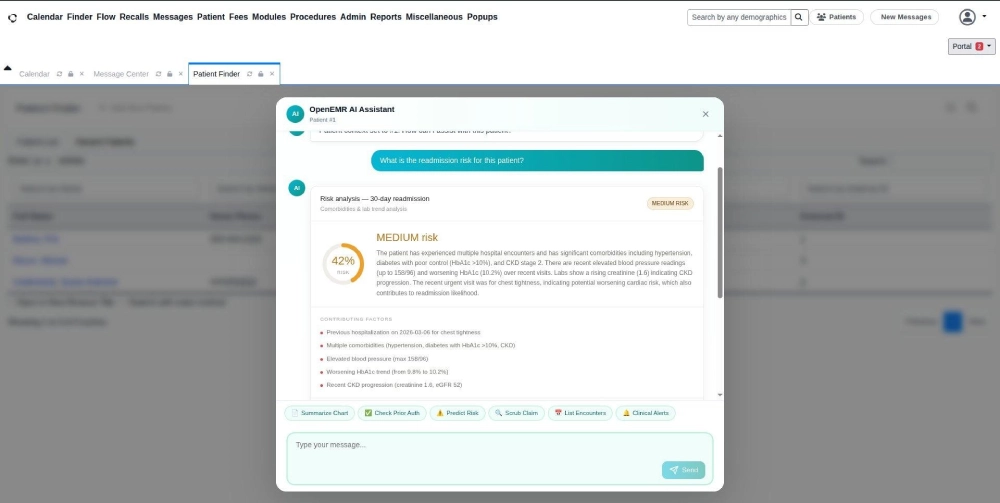
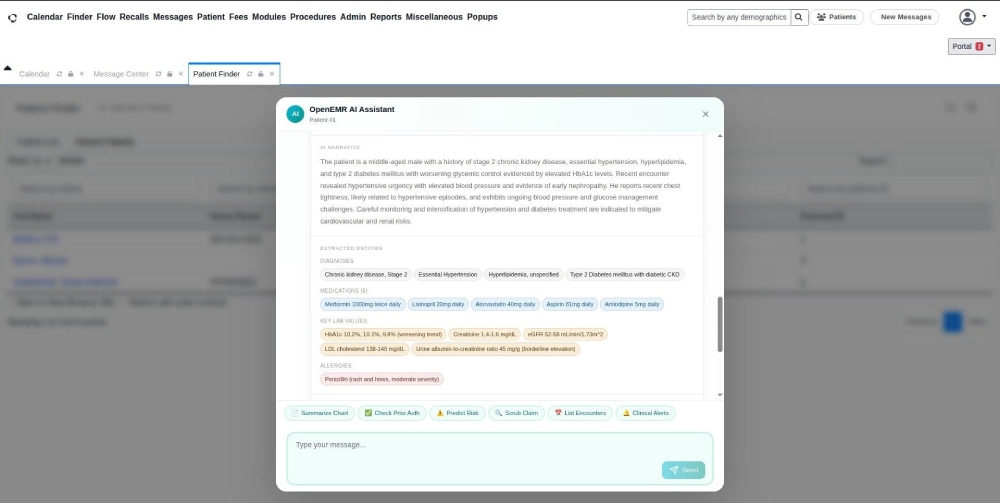
Step 5 – One-Click Chart Summarization
One click on the Summarize Chart generates a readable summary of the patient’s full medical history: current diagnoses, active medications, recent lab trends, and known allergies – all in a single, scannable view. What previously required several minutes of manual navigation now takes seconds.
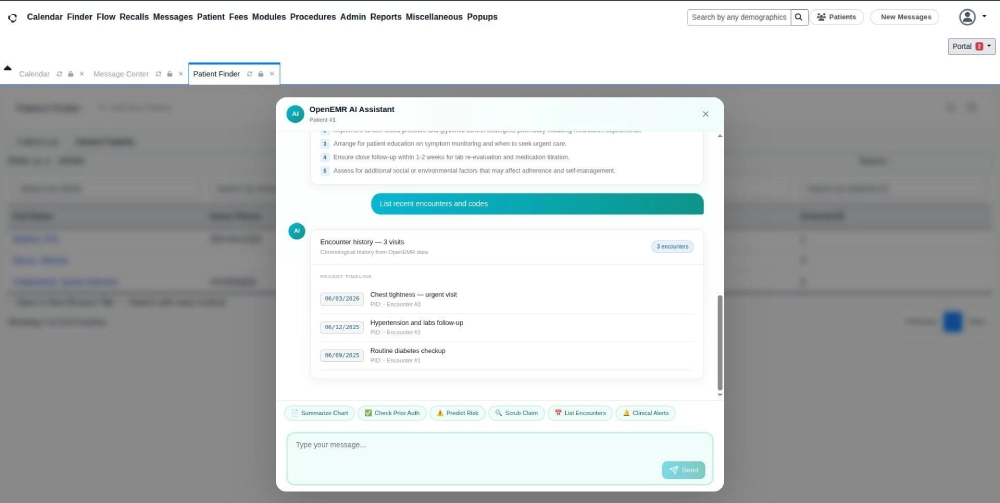
Step 6 – Full Patient Visit Timeline at a Glance
The chatbot pulls up a chronological list of every encounter on record. Visit dates, reasons, and progression visible in one scroll. Patterns like escalating conditions or missed follow-ups become immediately identifiable without opening individual records one by one.
Five Features That Separate This From a Generic Chat Interface
Designing a healthcare AI chatbot for clinics is not a user interface problem – it is an integration and workflow problem. Every feature we built was evaluated against one question: does this reduce a real, recurring burden for clinical staff, or does it only look impressive in a demo?
Patient Context Awareness – No Manual Entry, No Risk of Error
The AI knows which patient is selected from the moment the session starts. Every response is grounded in that patient’s actual records. Staff never repeat patient information manually or risk retrieving data for the wrong individual during a high-pressure part of the shift.
AI-Powered Risk Prediction for Decisions That Need to Happen Earlier
The AI analyzes a patient’s full history and surfaces readmission risk before a discharge decision is finalized. Clinical teams get the data they need to intervene proactively – not after an avoidable readmission has already occurred and generated a cost-of-care issue.
Instant Chart Summarization That Replaces Minutes of Manual Work
Complex medical records convert into a readable, structured summary in seconds. Information that typically requires a clinician to piece together from multiple system modules is now available on demand, at any point during a shift, with a single click.
Encounter Timeline That Makes Patient History Scannable
A chronological view of every patient visit makes it straightforward to identify recurring symptoms, missed follow-ups, or escalating conditions that would otherwise be buried across separate records, dates, and modules in the base system.
Quick Action Shortcuts That Compress Interaction Time
Predefined action buttons reduce how much staff need to type. Common clinical tasks become one-click operations. During high-volume clinic periods, that per-query time reduction compounds into significant hours recovered across the full team by end of shift.
The Technology Stack Behind the Integration – and Why Every Choice Mattered
Every technology choice was driven by a single evaluating question: will this work reliably inside OpenEMR, or will it introduce new conflicts that slow or break the clinical system?
The decision to implement LLM integration in healthcare apps via a decoupled Python backend was deliberate. It gives full control over how the AI processes patient queries, without being constrained by the frontend framework’s limitations inside an embedded environment.
| Layer | Technology | Why This Choice |
| Frontend | React.js | Lightweight, embeddable – no SSR conflicts with OpenEMR’s rendering lifecycle |
| Backend | Python | Strong AI and ML ecosystem; clean integration with LLM APIs and patient data pipelines |
| API Layer | REST | Simple, reliable, minimal overhead in embedded clinical environments |
| Host System | OpenEMR | Real-world clinical environment for accurate integration validation |
| Prior Attempt | Next.js + AI SDK | Abandoned – full-stack SSR is incompatible with embedded healthcare UI lifecycles |
The switch from Next.js to React.js was not a matter of preference. Embedded environments like OpenEMR control their own rendering lifecycle.
Frameworks that assume full-page ownership create conflicts with that lifecycle – and those conflicts will fail the integration. We validated this the hard way in Phase 1 and corrected course before it cost more time.
Architecture Decisions That Made This Stable Enough to Run in a Live Clinical System
Building a reliable AI solution for electronic health records environments requires clear architectural boundaries from the start. We separated the system into two fully independent layers so a change or failure in one could never cascade into the other.
Frontend – A Minimal Chat Interface Embedded Directly in OpenEMR
The frontend handles display and user interaction only. It does not manage AI logic or data retrieval. This makes it lightweight, stable, and straightforward to update without touching the backend – a critical property in clinical environments where downtime is not an acceptable outcome.
Backend – The AI Engine That Runs Independently of the Interface
The backend processes every query, retrieves the relevant patient data, and generates a context-aware response. It runs fully independently of OpenEMR’s frontend layer. The AI model can be upgraded or replaced entirely without any visible disruption to clinical staff workflows.
This separation is also central to operating a secure AI chatbot for medical records – patient data never flows through the frontend layer, and all AI processing happens in a controlled, isolated backend environment with appropriate access controls.
Three Design Principles That Kept the System From Breaking
- Avoided server-side rendering entirely – SSR creates direct conflicts with OpenEMR’s own UI lifecycle management
- Kept the frontend layer minimal – nothing in the interface that does not directly serve the user interaction
- Decoupled AI logic completely from the chat interface – two responsibilities, two independent components, one clean boundary between them
Every one of these decisions prioritized reliability over feature density. The validation results confirmed that the trade-off was exactly right.
Three Integration Failures We Hit – and Exactly How We Fixed Them
Challenge 1 – Framework Conflicts With OpenEMR’s Rendering Lifecycle
OpenEMR controls its own frontend rendering. Frameworks that assume they own the entire page create immediate and often unpredictable conflicts. Our first build exposed this critical incompatibility within hours of integration testing inside the actual system.
Switching to a lightweight React.js approach that works within OpenEMR’s constraints, rather than competing with them, was not a workaround. It was the architecturally correct solution for any embedded clinical system integration.
Challenge 2 – Overengineering Made the First Version Collapse Under Its Own Weight
Modern tooling adds layers of abstraction that embedded environments simply cannot absorb. Our first build with Next.js proved this early and clearly. We simplified aggressively – stripping the stack down to only what the chatbot genuinely needed to function reliably inside OpenEMR.
Feature restraint at the PoC stage is a sign of engineering maturity. Building more than you need to answer your hypothesis is how integration projects stall before they ever reach users.
Challenge 3 – Unpredictable Behavior Generated by the Embedded Environment Itself
Embedded systems are not standard web environments. They generate edge cases that are impossible to anticipate without hands-on testing inside the actual host platform. Configuration review and code analysis alone do not reveal them.
Decoupling the frontend and backend created a stable architectural boundary. Issues in one layer stayed contained and could not propagate into the other layer or destabilize the integration as a whole.

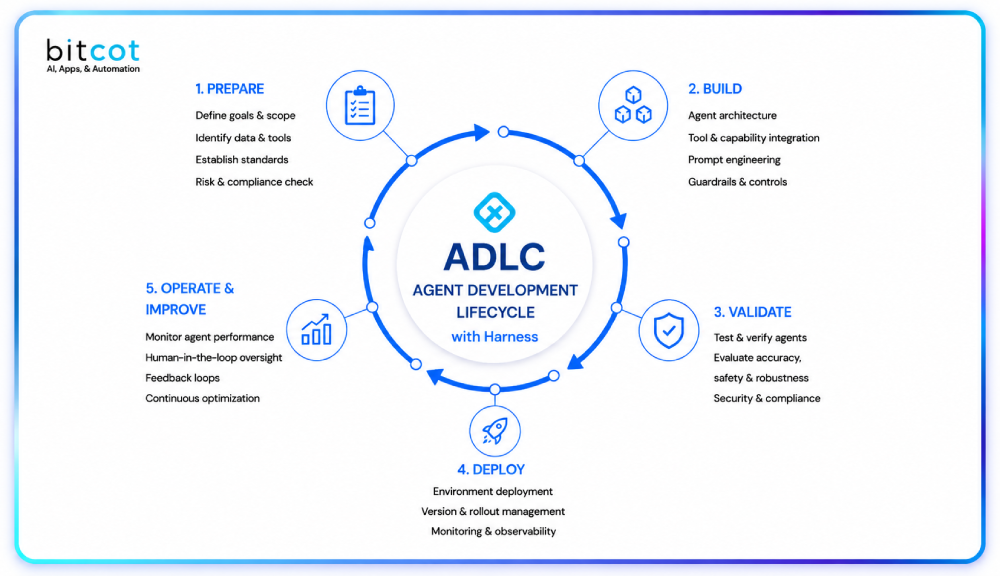
Four Development Phases: From a Build That Failed to a Prototype That Held
Phase 1 – Initial Build and Integration Failures
We started with a modern full-stack framework and hit integration failures quickly. The framework assumed control of the entire rendering environment – a fundamental incompatibility with how OpenEMR manages its own UI lifecycle.
Phase 2 – Root Cause Analysis and the Decision to Rebuild
We traced the failures back to the framework choice itself rather than our configuration. The correct path was not to patch the approach – it was to replace it with a stack designed for embedded deployment. Identifying this clearly saved weeks of wasted effort.
Phase 3 – Clean Rebuild With a Leaner, Validated Architecture
We rebuilt with a lightweight React.js frontend and a decoupled Python backend. Two independent layers, one clear responsibility each. The architecture was simpler than version one – and measurably more stable because of that simplicity.
Phase 4 – Validation Inside a Live OpenEMR Environment
The chatbot loaded consistently across every test session. Responses returned in near real-time. The AI handled patient-specific queries accurately using actual patient records. The PoC was complete and the EMR AI automation solution integration model was proven repeatable.
What the PoC Results Proved About AI Integration in Clinical Systems
For a broader view of what validated AI integration looks like in EHR environments, our team has documented additional findings in how AI agents are improving EHR systems in healthcare. The patterns mirror what we observed here.
Three Metrics That Confirmed the Approach Was Sound
- Load reliability: 100% consistent across all test sessions inside a live OpenEMR environment with real patient data
- Response time: Near real-time, with no noticeable lag for clinical staff at any point during interaction
- Accuracy: Context-aware responses drawn from actual patient records, not generic or templated outputs
What Simpler Architecture Made Possible
The simpler the architecture, the better it performed. Every layer removed during the rebuild made the system faster and more stable.
For any team evaluating a hospital AI assistant software integration, this is the most transferable lesson from our build: integration success consistently outperforms feature complexity inside embedded clinical systems.
Honest Limitations We Identified for the Next Phase
- AI reasoning is early-stage for this integration – complex multi-variable clinical queries will require a more capable language model
- Contextual depth is currently limited to structured patient data; unstructured clinical notes require a separate processing layer
These are not blockers. They are the natural, expected boundaries of a PoC – and exactly the kind of clarity a PoC is designed to surface before production investment is made.
Why an Embedded AI Chatbot Rewards Healthcare Organizations Long After Launch
A Modest Upfront Build That Keeps Giving Back
An initial integration of this scope sits in the low-to-medium range for development effort, which is small relative to the operational risk it removes. Server and infrastructure demands stay light.
The upfront work is about confirming one thing – whether an embedded AI layer behaves correctly inside your live system. Once that is proven, the same build keeps generating value shift after shift, long after the engineering work is complete.
Returns That Surface Every Day the System Runs
- Every clinical and administrative role spends less time on repetitive manual work during each shift
- Decisions at the bedside move faster because AI-synthesized patient data is available the moment it is needed
- New hires reach full productivity sooner because asking a question replaces learning a menu
- Help-desk volume drops as navigation, lookup, and basic usage questions stop reaching IT
According to a 2025 McKinsey survey of healthcare leaders, 64% of US healthcare organizations that have already implemented generative AI in their workflows report anticipated or measurable positive ROI from those deployments.
For any US healthcare organization evaluating an embedded AI chatbot, the question is no longer whether the investment works – it is how quickly it begins paying back, and how long the returns keep compounding after launch.
The payback window is short. And because the backend can scale independently of the chat interface, the same foundation keeps compounding as usage grows across departments – one build, expanding returns that extend well beyond launch.
The Strategic Case for Embedding AI in the Clinical Tools Your Team Already Trusts
Across America, healthcare organizations face consistent pressure: growing patient volumes, leaner staffing, and rising documentation requirements driven by billing complexity and compliance mandates.
A well-integrated AI-powered EMR system does not add to that burden. It reduces it by putting the right clinical information in front of the right person at exactly the right moment – without asking staff to learn a new system or change workflows they already rely on.
According to a 2025 HIMSS digital health survey, more than 60% of US healthcare executives now rank clinical AI integration as a top-three strategic priority – a significant increase from 34% reported in 2022.
Think of it the way GPS changed navigation. You could always get from A to B without it, but having clear and instant guidance made the journey faster, less stressful, and less prone to costly errors. An AI chatbot embedded in a clinical system does exactly the same thing for healthcare workflows.
The competitive advantage extends beyond efficiency gains. Organizations that reduce the administrative friction their clinical staff experience daily see measurable improvements in staff retention rates – in a market where experienced clinician turnover is both common and genuinely expensive to recover from.
What Comes After Validation – Building a Production-Ready Clinical AI System
The PoC validated the integration model. What follows is the layer of capability that transforms a working prototype into a genuinely powerful tool for clinical teams managing real patient loads at scale.
Capabilities We Are Adding to the AI Model
- A more capable language model that handles complex, multi-variable medical queries with greater clinical depth and contextual reasoning
- Real-time context awareness: the AI will recognize which patient or appointment is currently open in OpenEMR and adapt responses accordingly
- Plain-English summarization of free-text clinical notes and unstructured physician documentation
- Among the most requested future capabilities: tools that qualify as best ai chatbot platforms for automating appointment scheduling in healthcare – pre-visit reminders, slot availability checks, and follow-up booking all managed through the same chat interface staff already use
Role-Based Personalization for Every Clinical User Type
Responses will be tailored to the user’s role in the system. A physician needs clinical depth and diagnostic context. A receptionist needs scheduling clarity and appointment status. An administrator needs operational summaries. The AI will recognize the difference and adjust its output without any manual configuration per session.
What Organizations Need to Prepare Before Going to Production
- Data governance: Clear policies governing how AI-generated clinical outputs are reviewed and acted upon before decisions are made
- AI validation frameworks: Ongoing accuracy monitoring to maintain clinical reliability as the model learns from real usage over time
- Change management planning: Structured adoption processes so staff onboarding at scale goes smoothly and builds lasting confidence
These are not barriers to deployment. They are the foundation of a responsible production rollout that builds lasting trust with clinical teams from day one.
What Sets Our Approach to Healthcare AI Integration Apart
We did not just build a chatbot. We solved the specific embedded integration problem that causes most enterprise healthcare AI solutions to fail at the deployment stage – by respecting the constraints of a legacy system rather than engineering around them with increasingly complex workarounds.
Every healthcare project we take on is approached architecture-first: we validate the integration model before writing a single line of production code. We build with HIPAA guidelines in mind from the first conversation. And we only staff senior-level engineers on projects where the data involved carries clinical consequence.
Our healthcare AI agent development services are built around the same principles that drove this OpenEMR integration: validate first, architect for the real environment, and build systems that clinical teams actually want to use after deployment.
That is the difference between healthcare AI integration services delivered by a team that builds for how healthcare actually works, and AI development that happens to touch healthcare data without understanding the clinical environment it operates in.

The friction between how clinical software works and how healthcare staff need it to work is not a minor inconvenience. It is a daily, measurable drain on time, accuracy, and team wellbeing – one that multiplies across every role, every shift, and every patient interaction across your entire organization.
What we built inside OpenEMR demonstrates that AI does not need to be a large-scale infrastructure overhaul to deliver immediate clinical value.
A well-integrated, lightweight chatbot – built correctly from the start – gives your staff instant access to the right information, in the language they actually use, without changing a single workflow they depend on.
The technology is proven. The integration model is validated. The path from Proof of Concept to a production-grade AI-powered EMR system is clearly mapped. What determines whether this becomes a real operational asset in your organization is a single decision: when to start with something concrete.
Are you ready to stop tolerating the friction in your clinical workflows and actually solve it? If the answer is yes, the next step is simpler than you think – and it starts with a focused validation, not a six-month planning cycle.
If your healthcare organization is looking to turn complex compliance requirements and clinical workflow pressure into a scalable, AI-powered clinical experience, we can help.
Our healthcare AI integration services are built with HIPAA guidelines in mind and tailored to meet your specific clinical workflows, whether it is a legacy EMR modernization, a new embedded chatbot build, or a validated PoC before committing to a full production timeline.
- Validate your OpenEMR AI integration model in a real clinical environment with real patient data
- Confirm that AI responds accurately using your actual system structure and record format
- Build your production roadmap on proven architecture – not assumptions made in isolation from the actual environment
Connect with the Bitcot team to discuss your specific integration challenge. We help US healthcare organizations turn a clearly defined clinical problem into a working, validated solution – faster than most teams expect is possible.
Frequently Asked Questions (FAQs)
We integrate an AI chatbot with OpenEMR through a lightweight embedded frontend paired with a decoupled Python backend. The frontend lives inside OpenEMR’s interface while the backend runs independently, so AI upgrades never touch the clinical system. That separation is what keeps the integration stable. Yes, when the architecture handles patient data correctly. We process every query in an isolated backend with role-controlled access, and our builds adhere strictly to HIPAA regulations. Patient records never flow through the chat interface layer, which keeps the exchange within controlled boundaries. A validated working prototype typically takes a few weeks, not months. That short validation phase answers feasibility, integration, and accuracy questions before any production investment. Full rollout timing then depends on the number of departments and workflows in scope. Yes. The chatbot retrieves structured patient records, which the language model uses to generate context-aware responses. Every answer is grounded in the patient’s actual history, medications, and clinical notes rather than generic output. Yes. The architecture is portable, though each host system has its own rendering rules and API behavior. The integration model we proved inside OpenEMR transfers to Epic, Cerner, Athenahealth, and similar systems with specific adjustments to the embedding layer. Cost depends on scope, data integrations, and model capability. A validated initial build sits in the low-to-medium range for development effort. Enterprise rollouts across multiple departments scale from there based on the workflows being automated.
How does an AI chatbot integrate with OpenEMR?
Is it safe to use AI inside an EMR system?
How long does it take to build an AI chatbot inside OpenEMR?
Can the chatbot pull real patient data from OpenEMR?
Can this approach work with other EMR systems like Epic or Cerner?
How much does a healthcare AI chatbot cost to build?