Key Takeaways
- CB Insights data shows 38% of startups cite competitive pressure as a failure cause, but the real driver is almost always an architecture problem that slowed shipping to a crawl.
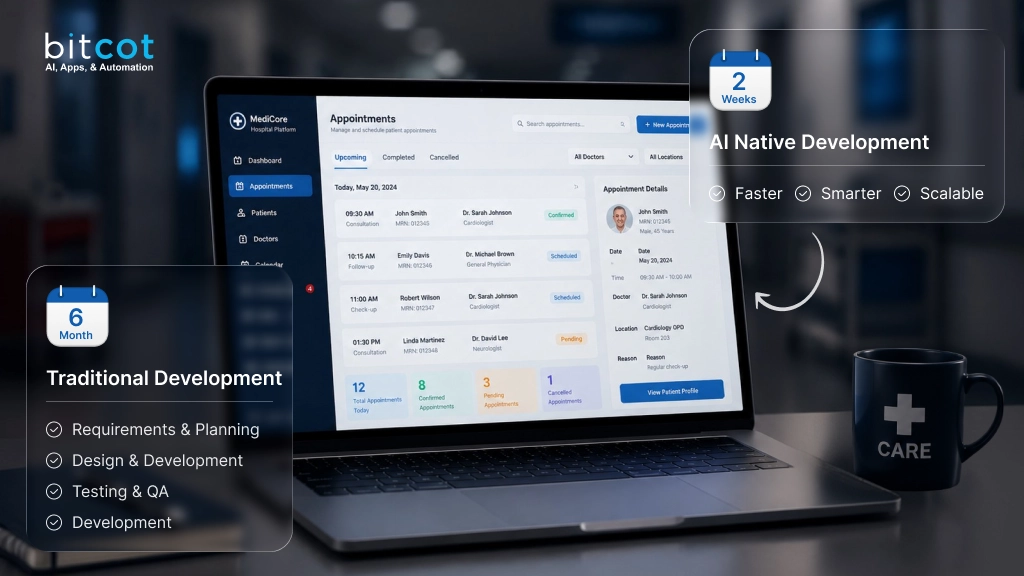
- Three decisions made in the first 90 days of SaaS development, namely single-tenant schema, synchronous-only APIs, and monolithic deployment, compound into platform failure by month 18.
- Technical debt crosses a compounding threshold when one feature change requires modifying three or more unrelated modules, after which velocity loss outpaces what hiring can fix.
- Google’s DORA research confirms that teams deploying fewer than once per week consistently show worse reliability outcomes, and monolithic deployment is the primary reason they end up there.
- In competitive markets like San Diego and Los Angeles, architectural bottlenecks translate to lost market position within 12 months, not 24, leaving almost no margin for delayed action.
Introduction
Most post-mortems on why SaaS projects fail point to market timing, funding shortfalls, or team dynamics. Those factors matter, but they rarely tell the full story. The products that lose to better-funded or faster-moving competitors are not outclassed on vision or user experience. They are outclassed on velocity: the ability to ship a critical fix in hours rather than weeks, or launch a differentiating feature in days rather than quarters.
That velocity gap is almost always an architecture problem that was never scheduled to be revisited. Across software development engagements serving California startups and San Diego technology companies, a consistent pattern emerges in struggling SaaS platforms. Three architectural decisions made during the first 90 days of development, each completely defensible at MVP stage, silently compound into a platform that cannot scale, cannot deploy reliably, and cannot evolve fast enough to stay competitive by month 18 to 24. This article explains what those three decisions are, how they interact to accelerate failure, and what a structured remediation path looks like in practice.
What Does SaaS Engineering Failure Actually Look Like?
SaaS engineering failure is not a single event. It is a gradual state in which adding new features consistently costs more than the value those features generate. That state has a measurable technical signature that most teams do not recognize until it has already crossed the compounding threshold.
The signature includes three indicators. Deployments stretch beyond one week. Test coverage on the most frequently modified modules falls below 60%. And every feature change triggers modifications across three or more modules that share no direct business relationship to the feature being built.
According to McKinsey Digital, companies that let technical debt accumulate without a managed repayment strategy redirect 10 to 20% of their technology budget to remediation work that produces nothing new for users. At high debt levels, that diversion reaches 40%. Those are not abstract percentages. For an engineering team trying to stay ahead of a well-funded competitor, that is the difference between shipping and stalling.
The Three Architectural Decisions That Drive Most SaaS Scaling Failures
None of these decisions are mistakes when they are first made. Each one is the rational choice for the stage and team size at the time. The problem is that the conditions justifying them expire, and there is rarely a system in place to catch that expiration before it starts costing real delivery speed.
Single-Tenant Schema Design
Early SaaS databases are typically built around a specific, small customer base. Tables use hard-coded identifiers, indexes are tuned for the first handful of workflows surfaced in user research, and the schema makes no provision for cross-account querying. At ten or twenty customers, this is entirely appropriate.
As the product reaches enterprise sales cycles, this design becomes a serious liability. Enterprise buyers expect cross-account dashboard views before committing to a purchase. Delivering those views on a single-tenant schema requires a full redesign of the data layer, not a new API endpoint. That redesign touches every data access component in the application, making it one of the costliest architectural changes a SaaS platform can face and one of the hardest to defer once the sales conversation requires it.
Synchronous-Only API Architecture
A synchronous API design makes every operation wait for a response before the next step proceeds. For low-volume, low-concurrency applications this is the right call: the behavior is predictable, the stack traces are readable, and the debugging cycle is short. The failure mode only emerges at scale, and it emerges suddenly.
When a third-party dependency slows during a traffic spike, every synchronous call waiting on that service holds a thread open. Under sufficient load, the thread pool exhausts and the entire application stops responding, not just the feature using the slow dependency. Retrofitting an async job queue into a fully synchronous codebase requires updating every service that makes downstream calls. In a mature application, that can mean coordinating changes across dozens of files with weeks of regression testing before any of it is safe to ship.
Monolithic Deployment Model
A monolith packages and deploys the entire application as one unit. For a small team working on a small codebase, this is operationally simple and perfectly reasonable. As both the team and the codebase grow, the monolith transforms from a convenience into a coordination tax.
A single failing test or unresolved bug in one module blocks every other team’s release. According to Google’s DORA State of DevOps Report, elite engineering teams deploy to production multiple times per day while low performers deploy less than once per week. Monolithic deployment is the leading architectural reason SaaS teams end up in the low-performer cohort. Full regression testing of the entire system is required for every release, regardless of how localized the actual change was.

How Does Technical Debt Compound in a SaaS Platform?
Most engineering problems respond to proportional solutions: more computing handles more load, more engineers close more tickets. Technical debt does not work that way. Once it crosses a compounding threshold, each unit of new debt generates additional debt at an accelerating rate that investment alone cannot reverse.
The first threshold is module coupling. When a single product change forces edits across three or more modules that have no direct relationship to the feature being built, those modules are implicitly sharing state or making behavioral assumptions about each other. Every subsequent feature added to that system deepens the coupling further, because engineers route around the existing entanglement rather than resolving it.
The second threshold is test coverage on high-churn modules. According to Stack Overflow’s Developer Survey, 62% of developers identify insufficient automated testing as the most significant driver of long-term velocity loss. When coverage on frequently modified modules drops below 60%, engineers can no longer safely refactor. Workarounds accumulate in place of clean solutions, and coupling accelerates with each sprint cycle.
Four Engineering Habits That Accelerate Technical Debt Accumulation
Beyond the three core architectural patterns, several common practices in early-stage SaaS teams push the compounding thresholds closer and faster than they need to arrive.
Launching Without API Versioning
A SaaS product without API versioning has no safe path to breaking changes. Every endpoint modification requires simultaneous coordination with every customer integration built against it. As the customer list grows, that coordination cost becomes prohibitive, which effectively freezes the API design. Engineers then build internal workarounds at the application layer rather than evolving the interface, adding weight to the codebase with every feature cycle.
When background jobs and multiple services write directly to shared tables instead of communicating through defined contracts or event streams, the database silently becomes the integration layer. Any schema optimization or migration then requires a full audit of every service touching those tables, many of which are not formally documented. Performance improvements accumulate as deferred debt instead of being addressed when they first appear.
Shipping Without Feature Flags
Feature flags separate the act of deploying code from the act of releasing it to users. Without them, incomplete or experimental work has to live in long-running branches that progressively diverge from the main codebase. The merge conflict work that accumulates creates exactly the kind of coordination overhead that slows release cadence from weekly to biweekly to monthly as the codebase matures.
Skipping Observability Infrastructure at Launch
A platform without structured logging, distributed tracing, and workflow-level alerting cannot diagnose production failures with speed or precision. When a scaling issue surfaces, the team reconstructs events from fragmented output rather than navigating instrumented data directly. Each incident handled this way reactively creates pressure toward quick patches rather than correct solutions, and that pressure gradually degrades the code quality that future stability depends on.

How to Fix SaaS Scaling Issues Without a Full Rebuild
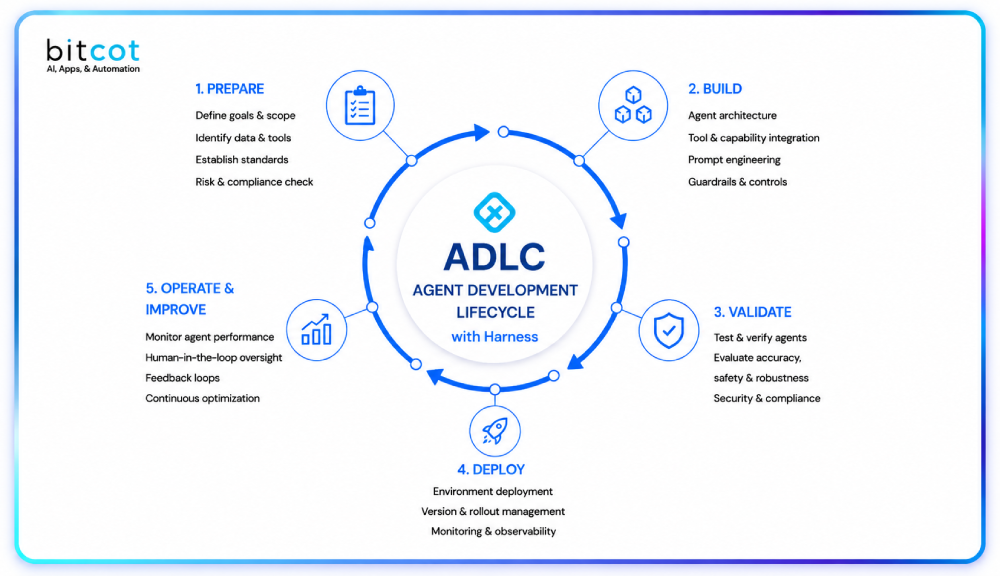
Addressing architectural debt in a live production platform requires sequencing the work to reduce risk at each step. The goal is not a clean-slate rewrite. It is a series of targeted interventions that progressively lower the blast radius of the next change while the platform continues serving active users.
Database Layer: Row-Level Tenant Isolation First
The lowest-disruption path to multi-tenant data architecture starts with row-level isolation rather than table restructuring. Adding a tenant_id column and enforcing tenant scope at the query layer allows the database’s query planner to index per tenant immediately, without touching existing table relationships. This migration runs one table at a time during dual-write windows, with tenant-scoped integration tests confirming each cutover before the old code path retires.
API Layer: Identifying and Offloading Deferrable Operations
Async migration begins with a classification pass: which operations sit on the user-facing response path, and which simply need to complete reliably? Notification dispatching, external system writes, and file processing are almost always deferrable without changing the API contract that existing callers depend on. Tools like BullMQ for Node.js, Celery for Python, or Sidekiq for Ruby handle retries, failure isolation, and load smoothing without requiring any changes to the synchronous endpoints that must remain on the critical path.
This architecture also matters directly for teams building AI/ML development features into their SaaS products. Inference calls are among the highest-latency operations any application can make. Keeping them on the synchronous request path is not viable at scale. Moving them to a background queue is a prerequisite for maintaining acceptable response times as usage grows.
Deployment Layer: Module Boundaries Before Microservices
Full microservice decomposition introduces significant new overhead: service discovery, inter-service authentication, distributed tracing across boundaries, and separate CI/CD pipelines per service. For most SaaS platforms at the scaling inflection point, that overhead is not yet justified. Enforcing clear interface boundaries within the existing monolith, prohibiting direct cross-module database access, and building independent test suites per module delivers most of the deployment reliability benefit at a fraction of the operational complexity.
Working with DevOps consulting specialists during this phase helps avoid introducing new bottlenecks while decomposing existing ones, especially when CI/CD pipelines must continue supporting active feature development throughout the transition.
What High-Performing SaaS Engineering Teams Do Differently
As Martin Fowler has noted, technical debt is not inherently a problem. It becomes a problem when it accumulates without a deliberate repayment strategy. The SaaS platforms that scale through the Series A inflection point share four habits that operationalize that strategy in practice.
They record architectural decisions at the moment they are made, not retrospectively. Each record captures the decision, the alternatives that were weighed, and the specific conditions that would justify revisiting it. When a database schema or API contract needs to change 18 months later, the team immediately knows whether the original logic still holds and whether the change is now warranted.
They treat deployment frequency as a tracked engineering health metric in every sprint review, not as a vague aspiration. A drop of more than 20% below baseline triggers an investigation into architectural causes before those causes become entrenched. Catching bottlenecks early is what keeps remediation proportionate.
They govern the critical request path explicitly. Any operation added to the per-request execution path requires a documented review and a performance regression test before it is merged. This prevents the gradual latency creep that makes a platform feel slow with no identifiable single cause, which is one of the earliest signals of customer churn that engineering teams miss.
They build custom software development practices that treat observability, testability, and deployment flexibility as first-sprint requirements rather than post-stability additions. Retrofitting these disciplines into a platform that has already accumulated debt across all three compounding categories is significantly more costly than building them in from the start.
What the First 90 Days Keep Getting Wrong Across SaaS Engagements
Across SaaS architecture engagements, particularly with San Diego and Los Angeles technology companies navigating the seed-to-Series-A transition, one observation repeats consistently. The original engineering team made defensible, correct decisions for the stage they were in. Single-tenant schemas are the right call at 50 accounts. Monolithic deployment is the right call at five engineers. The issue is not the decision itself.
The issue is that no one documented the conditions that would make those decisions obsolete. The signal to revisit an early architectural choice typically arrives 6 to 12 months before the team escalates it as a priority. By the time deployment friction is painful enough to interrupt the product roadmap, the debt has already crossed the compounding threshold where incremental fixes cost more than they recover.
In fintech and non-profit technology engagements, the teams that course-correct in time share one practice: they write explicit expiration conditions into their architectural decisions from day one. Notes like “revisit this schema when account count exceeds 500” or “evaluate async queuing if any synchronous operation exceeds two seconds at median load” are not complex to maintain. They are just rarely done. The digital transformation work that follows a stalled SaaS platform almost always begins by surfacing which founding decisions were never scheduled to expire.

Conclusion
Why SaaS projects fail at the architecture level is not a mystery. The root causes are consistent across post-mortems, the warning signals are measurable before they become critical, and the intervention points are well-understood. A platform showing the deployment frequency and test coverage patterns described in this article is not going through normal growth friction. It is approaching a compounding threshold where delay makes remediation exponentially harder.
The platforms that scale are not distinguished by superior initial architecture. They are distinguished by engineering teams that treated their early decisions as having explicit expiration dates tied to measurable conditions, and who acted when those conditions arrived rather than deferring until the slowdowns became crises. Accurate diagnosis is the starting point. A structured remediation path, sequenced to preserve platform stability throughout, is where the recovery actually happens.
Frequently Asked Questions
What is technical debt in SaaS development?
Technical debt in SaaS development is the accumulated cost of architectural shortcuts taken to move faster in the short term, specifically the design decisions that are correct at MVP stage but become obstacles to scaling as the product grows. In SaaS platforms, the most impactful forms are schema designs that prevent multi-tenant scalability, API patterns that block async processing, and deployment models that create release coordination bottlenecks. Unlike financial debt, technical debt does not grow linearly: it accelerates when it crosses measurable thresholds such as three or more modules modified per feature change or test coverage below 60% on high-change modules.
What is the difference between a SaaS scaling issue and normal performance degradation?
A SaaS scaling issue is structural: it appears consistently as user volume increases and cannot be resolved by adding more servers or increasing database resources without changing the underlying architecture. Normal performance degradation is environmental: it is caused by inefficient queries, missing indexes, or under-provisioned infrastructure that can be corrected without changing application design. The diagnostic test is whether the performance problem reappears at the same load threshold after infrastructure is upgraded. If it does, the problem is architectural and requires code-level intervention, not infrastructure scaling.
How do you fix scaling issues in a SaaS platform without a full rebuild?
Fixing SaaS scaling issues without a full rebuild requires sequencing three workstreams in order of blast radius. The database layer should migrate to row-level tenant isolation first, applying one table at a time with dual-write periods and integration test verification at each step. The API layer should classify operations by criticality and move deferrable work to background job queues without changing existing API contracts. The deployment layer should enforce module interface boundaries and independent test suites within the existing monolith before extracting any services, so that extraction can happen incrementally without disrupting release cadence for active feature development.
How do SaaS development challenges differ for startups in California?
SaaS startups in California, particularly in San Diego and Los Angeles, face a compressed failure timeline compared to less competitive markets. The concentration of well-funded SaaS competitors in the California technology ecosystem means architectural slowdowns translate to lost market position within 12 months rather than 24, because competing products can respond to market signals and ship improvements faster. California SaaS companies also operate in talent markets where senior engineering compensation creates pressure to maintain high developer productivity: architectural debt that slows an engineer’s daily output carries an outsized real cost relative to markets with lower engineering labor rates.
Is it worth fixing technical debt in a SaaS product, or is it better to rebuild?
Fixing technical debt is the right approach when the three compounding thresholds have not yet all been crossed simultaneously: deployment frequency is still above once per week, test coverage on frequently changed modules is still above 60%, and feature changes typically touch fewer than three unrelated modules. When all three thresholds have been crossed and the product has been in that state for six months or more, a targeted rebuild of the highest-debt subsystems is typically faster and lower-risk than attempting to refactor all three debt categories within a live production environment. The decision should be based on measuring the current state against these specific thresholds, not on the age of the codebase or the size of the engineering team.