Key Takeaways
- The average patient’s clinical record is distributed across five or more separate systems that cannot reliably exchange information, making data integration a foundational operational challenge.
- The 21st Century Cures Act mandated FHIR R4 API access for all certified EHR systems, but FHIR solves only data format problems, not semantic consistency or upstream data quality issues.
- Most health data aggregator projects fail due to early architectural decisions that underestimate data velocity and ingestion variability across source systems.
- Microservices-based healthcare data architectures deliver significantly better scalability and lower ongoing maintenance burden than monolithic aggregation layers.
- Well-executed healthcare data integration reduces duplicate clinical testing, accelerates care coordination, and lowers administrative overhead as data completeness improves.
Introduction
The average patient’s clinical data is distributed across five or more separate electronic health record systems that cannot reliably exchange information with each other. For hospital systems and health technology teams, that fragmentation directly causes duplicated clinical testing, delayed care coordination decisions, and administrative workflows that consume clinical staff time. Designing a healthcare data architecture that scales reliably as data volume grows and new source systems are onboarded is a fundamentally different engineering challenge from simply connecting two EHR systems.
The technical standards – FHIR, HL7, SNOMED, LOINC – are well-documented and widely supported. The decisions that determine whether the platform scales, stays maintainable, and delivers reliable data to downstream consumers are treated as secondary concerns far too often. The standard you implement matters far less than the pipeline architecture you build around it.
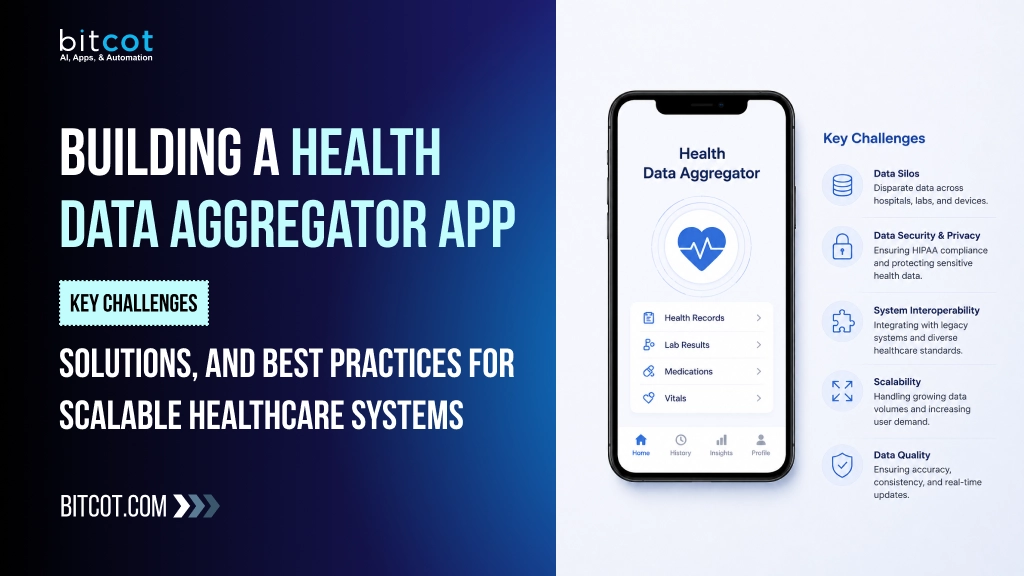
What Is a Health Data Aggregator and How Does It Work
A health data aggregator is a software system that collects clinical, operational, and administrative data from multiple disparate source systems – including electronic health records, laboratory information systems, pharmacy systems, claims databases, and remote monitoring devices. It normalizes that data into a consistent format and makes it available to downstream applications, analytics platforms, and care delivery workflows through a standardized query interface. The operational architecture of a health data aggregator typically spans four layers: ingestion, processing, storage, and serving.
The ingestion layer handles connections to source systems, which communicate through a mix of HL7 v2 message streams, FHIR REST APIs, flat file exports, and direct database reads from legacy EHR installations. The processing layer normalizes incoming records by resolving patient identity across systems, standardizing clinical codes to common terminologies such as SNOMED CT, ICD-10, and LOINC, and deduplicating records that arrive from multiple sources describing the same clinical event. The storage layer persists normalized data in a format optimized for the platform’s query patterns – typically a combination of a FHIR-native clinical data store and a columnar analytics warehouse.
The complexity of a health data aggregator is not in any single layer. It is in the interfaces between them – specifically in how data flows between layers, how failures at any layer are handled without corrupting downstream data, and how the system recovers when a source system changes its output format without notice.
Core Challenges in Healthcare Data Architecture That Stall Most Projects
Most healthcare data aggregator projects that fail do not fail because the team chose the wrong database or the wrong cloud provider. They fail because the architecture was not designed to absorb the specific types of variability that healthcare data generates at scale. Understanding the failure modes in advance is the most effective form of risk mitigation.
Semantic inconsistency across source systems. A patient’s diagnosis of hypertension may appear as the ICD-10 code I10, the SNOMED code 38341003, a local lab code, or as free text in a clinical note, depending on which EHR system originated the record. A health data aggregator must map all of these representations to a consistent internal concept before any cross-system analysis is meaningful. Building and maintaining that mapping, which grows as new source systems are added, is often underestimated in initial project scoping.
Patient identity resolution across disconnected systems. The same patient may exist under different medical record numbers in an inpatient EHR, an outpatient clinic system, and a pharmacy platform within the same health system. Matching those records to a single patient identity requires probabilistic matching algorithms that handle name variations, date-of-birth discrepancies, and missing demographic fields. Errors in identity resolution propagate downstream into every analysis built on the aggregated data.
Data velocity varies by orders of magnitude across source types. A laboratory information system may push hundreds of result messages per hour during peak clinical hours. A remote monitoring platform may stream continuous vital sign data at sub-minute intervals. A claims system may deliver batch file exports once per day. A healthcare data pipeline designed around one of these cadences without accounting for the others will develop bottlenecks, processing delays, or storage cost problems as additional source systems are connected.
Source system changes without advance notice. EHR vendors release updates that alter message formats, add or remove fields, and change code mappings on schedules that do not align with the downstream systems consuming their output. A health data aggregator that lacks a schema validation layer at ingestion will silently process malformed records that corrupt downstream analytics until the error is noticed, sometimes weeks after the malformed data entered the pipeline.
FHIR Data Standards in Healthcare: What They Solve and What They Do Not
The Fast Healthcare Interoperability Resources (FHIR) standard, maintained by HL7 International, defines a set of structured data resources, including Patient, Observation, Condition, Medication, Encounter, and more than 150 others, and specifies how those resources should be exchanged through REST APIs. FHIR R4 became the federally mandated standard for certified EHR systems following the 21st Century Cures Act’s information blocking rules, which took effect in 2021 and require EHR vendors to provide FHIR API access to patient data without charge.
FHIR solves a real and significant problem: it gives health data aggregators a common integration surface across EHR systems that previously required custom HL7 v2 parsers for each vendor. Instead of writing bespoke integration code for Epic, Cerner, Meditech, and athenahealth separately, a FHIR-enabled aggregator can use a single API client that speaks to all of them through the same resource model. That reduction in integration surface area is not a small benefit: it is the primary driver of decreased EHR integration cost over the past five years.
What FHIR does not solve is equally important to understand before designing a healthcare data architecture around it. FHIR defines the structure of data resources but does not enforce consistent clinical coding across vendors. Two EHR systems may both return a valid FHIR Observation resource for a patient’s blood pressure while using different LOINC codes, different unit representations, or different reference ranges. The aggregator must still normalize those semantic differences. FHIR also does not address data quality problems that originate in the source EHR: missing values, incorrect mappings, and outdated records arrive in FHIR format with the same frequency they arrived in HL7 v2 format. The standard changes the container; it does not improve the contents.

Building a Scalable Healthcare Data Pipeline: Architecture Decisions That Determine Outcome
The architectural decisions that most influence whether a healthcare data platform scales gracefully or develops structural problems are made in the first few weeks of design. Getting them right requires reasoning about how the system will behave when data volume is ten times current estimates and source system count has tripled, not just what it needs to do today.
Streaming versus batch ingestion. Healthcare use cases span a wide range of data freshness requirements. Sepsis detection and medication alert systems need near-real-time data; population health analytics and care gap reporting can tolerate latency measured in hours or days. A healthcare data pipeline designed with only one ingestion model will either over-engineer the infrastructure for batch use cases or fail to meet latency requirements for clinical use cases. Production-grade platforms separate these paths at the ingestion layer, using event streaming for time-sensitive clinical data and scheduled batch processes for administrative and claims data, with a unified normalized output that downstream consumers query regardless of which ingestion path produced a given record.
Schema validation at the ingestion boundary. Every record entering the pipeline should be validated against a defined schema before it proceeds to normalization. Records that fail validation should be routed to a quarantine queue with structured error metadata rather than silently dropped or passed through with missing fields. This prevents data quality issues from compounding downstream and creates an auditable record of source system data quality over time, a dataset that is itself useful for identifying which source systems require upstream attention.
Terminology service as a shared infrastructure component. The code mapping logic that translates between ICD-10, SNOMED, LOINC, RxNorm, and local facility codes should be built as a shared service that every processing stage queries, rather than as logic embedded in individual pipeline stages. When code mappings need to be updated, which happens with every ICD revision cycle, a centralized terminology service means the update is made once and propagates automatically, rather than requiring changes across multiple pipeline components. Teams building custom software development for healthcare data platforms consistently cite decentralized terminology management as one of the most expensive architectural mistakes to unwind later.
FHIR store selection aligned to query patterns. FHIR-native data stores optimized for clinical queries handle individual patient record retrieval efficiently, but are not designed for the aggregated analytics queries that population health use cases require. A scalable health data management system typically maintains both a FHIR store for clinical access patterns and a columnar data warehouse for population-level analysis, with a pipeline that synchronizes between them on a defined schedule. Designing these as a single store creates performance problems that grow as data volume increases.

Microservices Healthcare Architecture vs. Monolithic: Choosing the Right Fit
The decision between a microservices-based healthcare data architecture and a monolithic aggregation layer is not a question of which is more modern. It is a question of which deployment model matches the team’s size, the diversity of source systems being integrated, and the expected rate of change in both.
Microservices architecture makes sense for health data aggregators when different source systems require meaningfully different ingestion logic that would be difficult to maintain in a shared codebase; when different pipeline components have different scaling requirements, with ingestion needing to scale independently from normalization or storage; when multiple teams are working on different pipeline components in parallel and need independent deployment cadences; and when the platform is expected to onboard new source system types over time that are not yet known at design time. The tradeoff is operational complexity: each service boundary is also a failure boundary, and distributed systems require more sophisticated monitoring, retry logic, and circuit-breaker patterns than monolithic systems.
Monolithic architecture makes sense for early-stage platforms integrating a small number of source systems with a single small team, where the operational overhead of service orchestration would slow development more than the architecture would help. The path from monolith to microservices is well-understood and executable when the platform grows to the point where the monolith becomes a bottleneck. For teams building an enterprise healthcare system architecture for the first time, starting with a well-structured monolith and extracting services as the need becomes clear is often the lower-risk choice.
The AI/ML development components of a healthcare data platform, including clinical NLP for extracting structured data from unstructured notes, anomaly detection for data quality monitoring, and predictive models for care management, are almost always better deployed as separate services regardless of the overall architecture choice. Their compute requirements differ fundamentally from those of the data pipeline components, and their deployment cadence is driven by model retraining cycles rather than feature releases.
How Healthcare Data Integration Reduces Hospital Costs and Improves Operational Outcomes
According to McKinsey’s healthcare digital research, healthcare organizations that achieve genuine interoperability across their clinical and administrative data systems realize measurable operational improvements in three primary categories: reduced redundant clinical testing ordered because a prior result was not accessible to the ordering clinician; faster care coordination decisions enabled by a complete clinical picture available at the point of care; and reduced administrative overhead from manual data reconciliation that is eliminated when systems share a common source of truth.
Duplicate laboratory and imaging orders are a particularly high-value target for data integration. When a patient’s prior results are inaccessible to a clinician in a different system, the default clinical decision is often to repeat the test to ensure current data is available. According to HIMSS research on healthcare interoperability value, a significant portion of diagnostic testing in fragmented health systems involves redundant orders that would not have been placed if prior results had been accessible. The value of eliminating even a fraction of those redundant orders compounds across a health system’s entire patient volume.
Operational efficiency gains from reduced manual reconciliation are equally significant. Care coordinators, billing staff, and clinical documentation specialists in fragmented systems spend substantial portions of their time retrieving, copying, and re-entering data between systems that cannot communicate directly. A well-designed health data aggregator eliminates the majority of that manual transfer, redirecting staff capacity toward activities that require human judgment rather than data movement. The telemedicine software development programs that have delivered the strongest operational returns are consistently the ones backed by a data integration layer that makes complete patient records available at the point of virtual care without requiring the clinician to query multiple systems manually.

Best Practices for Enterprise Healthcare System Architecture
The following practices reflect patterns that consistently distinguish healthcare data platforms that scale from those that require significant rearchitecting within two years of launch.
Design for source system failure from day one. Source systems in healthcare environments go offline for maintenance, change their output formats, and occasionally push malformed data during EHR upgrades. A healthcare data pipeline that assumes source availability and data quality will develop reliability problems that are difficult to diagnose after the fact. Circuit breakers, dead-letter queues, and source system health monitoring should be part of the initial design, not retrofitted after the first production incident.
Maintain a patient master index as a first-class service. Patient identity resolution is the foundational data quality operation in any health data aggregator. Organizations that treat it as a preprocessing step embedded in the ingestion pipeline rather than as a managed service with its own data store, matching algorithm versioning, and human review workflow consistently encounter patient record merge errors that are expensive to detect and correct. An OpenEMR development integration built without a well-designed patient master index frequently surfaces duplicate patient records in clinical workflows months after launch.
Version your data schemas and your APIs independently. Source systems and downstream consumers will both change their data contracts over time. A healthcare data platform that allows these changes to propagate directly will create dependency chains that make any modification a system-wide coordination problem. Versioning schemas at the ingestion boundary and versioning the query API independently gives each layer room to evolve without breaking its neighbors.
Instrument data lineage from ingestion to output. Clinical and analytical consumers of aggregated health data need to be able to trace where a given data point originated, when it entered the platform, and what transformations it underwent. Data lineage is a reliability requirement for clinical use cases and an operational requirement for debugging data quality issues. Building lineage tracking from the start is an order of magnitude less expensive than retrofitting it after the platform is in production.
Treat the terminology service as a living system, not a one-time build. Clinical code sets such as ICD, SNOMED, LOINC, and RxNorm are updated on regular release cycles, and local facility codes change as departments modify their workflows. A terminology service updated manually and infrequently becomes a source of silent data quality degradation. The service should be designed with automated update pipelines for standard terminologies and a governance workflow for local code changes.
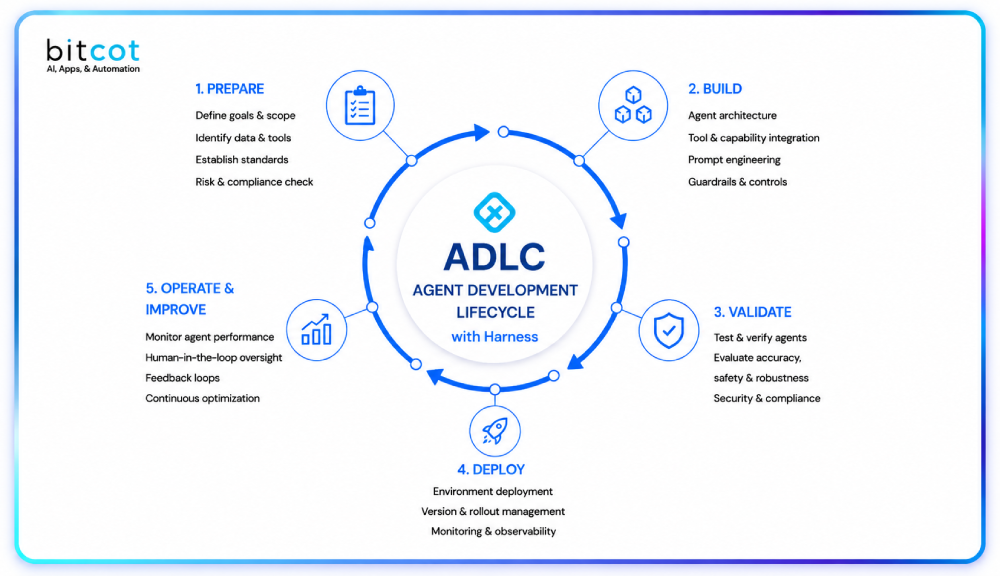
What Engineering Teams Get Wrong Before Writing a Single Line of Code
Working on a healthcare data platform that builds across San Diego’s health technology sector, we see a consistent pattern in how projects get scoped. The initial requirements focus on which EHR systems need to be connected and what data needs to be available to downstream consumers. Those are the right questions. The questions less often asked upfront are the ones whose answers determine whether the platform still performs well eighteen months after launch: how will we handle source system outages, how will we manage patient identity conflicts across systems, and how will we update code mappings when ICD releases a new revision.
The teams that build healthcare data aggregators that hold up under production load treat data quality and operational reliability as architecture requirements rather than operational afterthoughts. Starting a healthcare data architecture engagement with those questions on the table, rather than discovering them mid-build, is the single most impactful thing a team can do to improve the probability of a successful outcome. That focus is central to every data infrastructure engagement our team takes on.

Conclusion
Building a scalable health data aggregator requires getting three things right in the right order: the standards layer that enables connections to source systems, the pipeline architecture that translates those connections into reliable and consistent data, and the operational design that ensures the platform holds up when source systems behave badly or data volume exceeds early projections. FHIR has resolved a significant portion of the first problem. The second and third are architectural and engineering problems that no standard solves on its own.
Healthcare organizations and health technology teams that approach this work with that sequence in mind, starting with standards, then architecture, then operational resilience, build platforms that deliver compounding value as more data sources are connected and more downstream use cases are unlocked. Those that start with use cases and work backward without addressing the architecture layer in between build systems that work in demos and struggle in production. The difference between those two outcomes is the design work that happens before the first line of code is written.
Frequently Asked Questions
What is a health data aggregator app?
A health data aggregator app is a software platform that collects clinical, administrative, and operational data from multiple disconnected healthcare source systems, including EHRs, laboratory systems, pharmacy platforms, and claims databases, normalizes it into a consistent format, and makes it queryable through a standardized interface for downstream applications and analytics. As described in this article, the aggregator spans four layers: ingestion, normalization and processing, storage, and serving. The technical complexity lies not in any single layer but in the data quality, patient identity resolution, and pipeline reliability requirements that span all four layers simultaneously.
What is the difference between HL7 and FHIR in healthcare data integration?
HL7 v2 is the older messaging standard that healthcare systems have used for decades to exchange clinical events such as lab results and admission notifications through point-to-point message streams, while FHIR is a modern REST API-based standard that structures health data into defined resources and enables query-based access to complete patient records. As this article explains, FHIR became the mandated standard for certified EHR systems following the 21st Century Cures Act and provides a common integration surface that significantly reduces the custom code required to connect multiple EHR vendors. The important distinction is that both standards define data exchange format but not data quality or semantic consistency, and those remain problems that the health data aggregator architecture must resolve regardless of which standard the source system uses.
How does a healthcare data pipeline work?
A healthcare data pipeline ingests raw clinical and administrative data from source systems, validates it against defined schemas at the ingestion boundary, routes it through normalization processes that resolve patient identity, standardize clinical codes, and deduplicate records from multiple sources, then persists the normalized output to a data store that supports the downstream query patterns required by clinical and analytical consumers. As this article describes, production-grade healthcare data pipelines separate streaming ingestion for time-sensitive clinical data from batch processing for administrative and claims data, and maintain a centralized terminology service that all normalization steps query rather than embedding code mapping logic in individual pipeline components. This separation is what allows the pipeline to scale as new source systems are added without requiring rewrites of the normalization layer.
How are hospitals and health systems in San Diego approaching patient data integration?
Healthcare organizations in San Diego are approaching patient data integration with a growing emphasis on FHIR-based connectivity following the 21st Century Cures Act mandates, combined with microservices-based pipeline architectures that allow different source system integrations to be developed and scaled independently. The pattern observed among San Diego health technology teams is a shift away from monolithic aggregation layers built for a fixed set of source systems, toward modular healthcare data architectures designed to onboard new data sources without requiring changes to the normalization or serving layers. This architectural flexibility has become a priority as health systems expand their connected care programs and need to integrate data from remote monitoring devices, patient-facing applications, and specialty clinic EHR systems that were not part of the original integration scope.
Is the ROI of healthcare data integration worth the complexity and investment?
The ROI of healthcare data integration is well-supported by research and operational data from health systems that have completed integration programs, with primary value drivers including reduced duplicate clinical testing when prior results become accessible across system boundaries, faster care coordination decisions enabled by a complete patient clinical picture, and elimination of the manual data reconciliation work that consumes significant clinical and administrative staff capacity in fragmented environments. As this article describes, these outcomes compound as data completeness improves: each additional source system connected increases the value delivered to all downstream consumers. Organizations that approach the project with the right healthcare data architecture from the start consistently achieve better outcomes and spend significantly less on course corrections than those that treat architectural decisions as secondary concerns during the initial build.