Key Takeaways
- LLM selection is the least consequential AI SaaS architecture decision.
- Orchestration layer design determines latency, cost, and reliability at scale.
- Feedback loop infrastructure separates improving products from static ones.
- San Diego AI SaaS teams are choosing hybrid inference to manage costs.
- Data pipeline architecture, not model choice, drives real product differentiation.
Introduction
According to Gartner, worldwide AI software revenue is projected to reach $297 billion by 2027, and a significant portion of that growth is being captured by SaaS products that embed AI as a core capability rather than a feature add-on. What the growth forecasts do not capture is how many of those products, a saas product nobody tells you about quietly fail at the infrastructure level – not because the AI model was wrong, but because the engineering decisions surrounding it were poorly sequenced. Teams building AI SaaS products in San Diego and across California’s technology corridor are encountering a specific, recurring pattern: they spend months selecting and fine-tuning an LLM, then discover that the model was never the bottleneck. The real decisions – orchestration, data pipeline design, state management, and feedback loop architecture – are the ones that determine whether a product can serve a hundred users or a hundred thousand. This article examines each of those layers, draws on patterns observed across production AI SaaS builds in healthcare and fintech, and surfaces the engineering tradeoffs that most launch-focused teams only discover after they are already in production.
Why the LLM Is the Wrong Starting Point for AI SaaS Architecture
Most AI SaaS architecture conversations start with a single question: which LLM should we use? The framing is understandable but structurally backwards. A language model is a compute endpoint, and like any endpoint, its behavior in production is shaped entirely by what surrounds it. Choosing GPT-4o over Claude 3.5 Sonnet before designing the prompt orchestration layer is roughly equivalent to selecting a database engine before defining the data access patterns – technically a decision, but not yet a meaningful one.
The orchestration layer is where the actual product logic lives. It determines how user input is preprocessed, how context is assembled and trimmed, which tool calls are invoked in sequence, how retries and fallbacks are handled, and how the model’s output is validated before it reaches the user. Teams that treat orchestration as a glue layer rather than a first-class architectural concern consistently produce AI SaaS products with unpredictable latency, inconsistent output quality, and inference costs that do not scale alongside revenue.
In healthcare SaaS builds, this distinction is especially consequential. A product that summarizes clinical notes or assists with prior authorization workflows cannot tolerate hallucinated output passed directly to users. The orchestration layer must include a structured output validation step, a fallback routing decision, and, in many cases, a secondary verification pass before anything surfaces in the interface. None of those requirements is visible when the only question on the table is which model to call.

What Does an AI SaaS Tech Stack Actually Need in 2026?
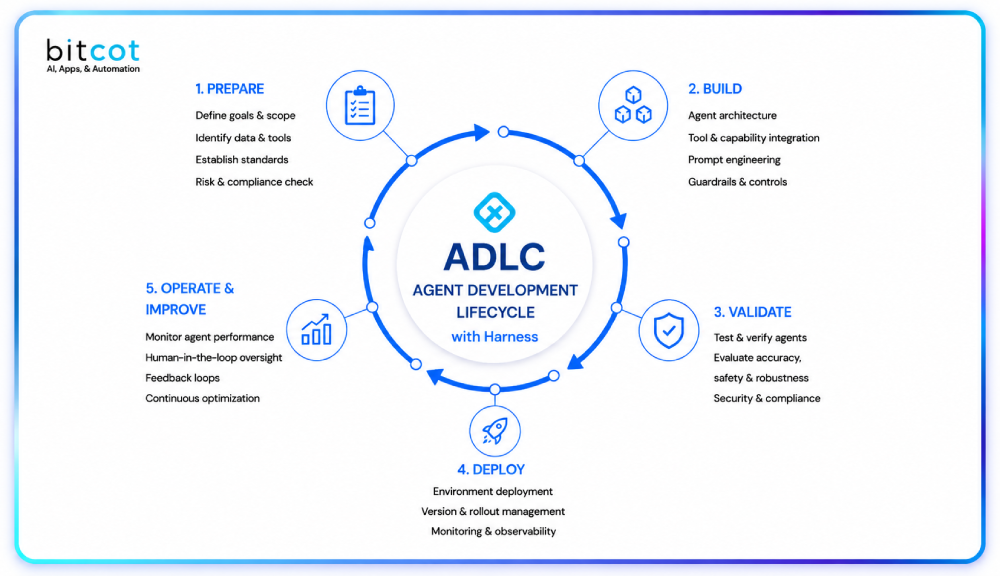
An AI SaaS tech stack in 2026 is not a single-model deployment. It is a multi-layer system in which the language model is one component sitting inside a larger architecture that handles context management, retrieval, tool use, output verification, observability, and continuous model improvement. Each layer has its own tooling choices, failure modes, and performance tradeoffs.
The core layers, in the order they affect product behavior, are:
- Data ingestion and normalization pipeline: Responsible for converting raw user data into a format the model can reason over. In fintech SaaS, this often means normalizing transaction records, merchant categories, and account hierarchies. The quality of output is directly bound by the quality of this layer. No amount of prompt engineering compensates for a poorly normalized data schema.
- Retrieval-augmented generation (RAG) infrastructure: The mechanism by which the product grounds model responses in the user’s specific data rather than general training knowledge. Vector database selection (Pinecone, Weaviate, pgvector as a Postgres extension) matters far less than the chunking strategy, embedding model consistency, and re-ranking logic applied before context is assembled.
- Orchestration framework: The runtime that sequences model calls, tool invocations, and branching logic. LangChain and LlamaIndex are the most commonly adopted options, though teams building high-throughput SaaS products are increasingly migrating to lighter, purpose-built orchestration layers to avoid the overhead and abstraction leakage these frameworks introduce at scale.
- Inference routing and cost control: The layer that decides which model to call for which request type. A well-designed AI SaaS product uses a tiered inference strategy: simple classification or extraction tasks route to smaller, faster, cheaper models; complex generation or reasoning tasks route to frontier models. Flat routing to a single frontier model for all request types is the most common cause of unsustainable inference cost structures.
- Feedback loop and evaluation infrastructure: The layer that most teams skip entirely until they are in production and discover that model performance is drifting. This includes structured logging of input-output pairs, human review workflows for edge cases, automated evaluation against a golden dataset, and the pipeline to incorporate corrections back into system prompt updates or fine-tuned model versions.
Building these layers in sequence, with deliberate interface contracts between them, is what separates an AI SaaS product that compounds improvement over time from one that is permanently frozen at its day-one capability level.
The Hidden Cost Problem Nobody Budgets For
Inference cost is the financial structure of an AI SaaS product, and it behaves in ways that traditional SaaS unit economics do not prepare founders or engineering leads to anticipate. In a conventional SaaS product, compute cost scales roughly linearly with user count and usage volume. In an AI SaaS product, inference cost scales with token consumption, which is a function of context window size, prompt engineering decisions, and the routing logic described above. None of these variables is obvious from the product interface.
According to AI SaaS companies are spending between 20 and 40 percent of their revenue on model inference at early scale, a ratio that makes the traditional SaaS gross margin profile structurally unachievable without deliberate cost architecture. The teams that solve this problem are not doing so by choosing cheaper models. They are doing so by redesigning what goes into the context window on every request.
Two specific patterns drive disproportionate token consumption in production AI SaaS. First, full document injection: teams that load entire documents into context on every request because the retrieval layer is not filtering precisely enough. Second, runaway system prompt growth: system prompts that accumulate instructions over time without a structured pruning process, growing to thousands of tokens for requests that could be handled with a few hundred. Both patterns are invisible from the product surface and show up only in the billing dashboard after the damage is done.
Teams building AI-native product development architectures are solving this by treating token budget as a first-class product requirement – assigning a token ceiling to each request type during design, not after deployment.
How Is Building an AI SaaS Product Different From Traditional SaaS Development?
Building an AI SaaS product differs from traditional SaaS development in one structural way that cascades across every engineering decision: the system’s behavior is not fully deterministic, which means traditional quality assurance frameworks are insufficient on their own. In a conventional SaaS product, a given input reliably produces the same output. In an AI SaaS product, the same input can produce different outputs depending on model temperature, context window state, and API version. Testing strategies, deployment practices, and user trust design all need to account for this.
State management is the most underestimated consequence of this difference. Traditional SaaS products manage application state: session data, user preferences, transactional records. AI SaaS products must also manage conversation state, model context state, and evaluation state across a session boundary that the underlying model does not natively preserve. Every context management decision – what to include, what to summarize, what to drop – directly affects both output quality and inference cost simultaneously. That dual dependency has no equivalent in conventional application architecture.
The deployment model also changes significantly. Traditional SaaS teams ship a release and observe error rates and latency metrics. AI SaaS teams ship a release and must simultaneously observe model output quality, which requires either human review infrastructure or automated evaluation tooling that most teams have not built before their first production deploy. Teams referencing how to develop an AI system with production-grade quality controls often find that the evaluation infrastructure is as complex to build as the product itself.

The Data Layer Is Where Real Differentiation Lives
Every AI SaaS product built on a third-party LLM shares the same underlying model capability as every competitor using that same model. The only layer where genuine, defensible product differentiation can be engineered is the data layer: what proprietary data the product ingests, how it is structured for retrieval, and how it accumulates and improves over time through user interaction.
This is a structural observation that has significant implications for product strategy. Teams that compete purely on prompt engineering are competing on a surface that any well-resourced competitor can replicate in weeks. Teams that build a proprietary data layer – a corpus of domain-specific documents, a structured feedback dataset from real clinical or financial workflows, a continuously improving evaluation ground truth – are building a moat that compounds with every production interaction.
In healthcare AI SaaS specifically, this data layer architecture intersects directly with how patient information is handled in the system. The engineering question is not whether to use patient data for model improvement – it is how to design the data pipeline so that the system learns from interaction patterns, output corrections, and clinician feedback without requiring the raw underlying records to leave a controlled data environment. That distinction shapes every choice from storage architecture to the API boundary design between the AI layer and the application layer. For teams working on healthcare web application development, the data layer architecture is not a back-end concern – it is a product strategy decision made before a line of code is written.
Multi-Tenancy in AI SaaS Is More Complex Than Traditional SaaS
Traditional SaaS multi-tenancy is primarily a database isolation problem: row-level security, tenant-scoped queries, and access control policies. In AI SaaS, multi-tenancy extends into the model layer, and the isolation requirements are harder to enforce. Vector stores, RAG pipelines, system prompts, fine-tuned models, and feedback datasets all carry tenant-specific data that can cross-contaminate if the architecture does not enforce strict namespace isolation at every layer.
The most common multi-tenancy failure mode in production AI SaaS is vector store contamination: a retrieval query for one tenant surfaces document chunks from another tenant’s corpus because embedding indices were not partitioned by tenant at ingestion time. This failure is particularly damaging in healthcare and fintech SaaS, where the surfaced data may include sensitive records. Teams exploring how to build multi-tenant SaaS on AWS with AI components need to treat vector store partitioning as a first-class architecture requirement, not an afterthought addressed during security review.
Fine-tuned models introduce a secondary multi-tenancy challenge. When a model is fine-tuned on one tenant’s data to improve domain-specific performance, the resulting model weights carry implicit knowledge of that tenant’s data distribution. Sharing fine-tuned model versions across tenants is a data isolation decision, not just a performance one. This requires organizations to decide upfront whether they are building a shared-model architecture with tenant-specific prompt engineering, or a per-tenant model architecture with higher infrastructure complexity and cost.
Observability for AI SaaS Is Not Application Monitoring
Traditional application monitoring tracks error rates, response times, throughput, and resource utilization. These metrics are necessary for AI SaaS but not sufficient. An AI SaaS product can return a 200 HTTP response with sub-100ms latency and still be producing factually incorrect outputs, tonally misaligned, or structurally broken for downstream consumption. None of that failure is visible in a standard application monitoring dashboard.
AI-specific observability requires logging and evaluating at the semantic layer, not just the infrastructure layer. According to IBM, AI observability encompasses monitoring model inputs, outputs, and drift patterns over time – capabilities that require purpose-built tooling separate from conventional APM platforms. The practical implication for AI SaaS teams is that launching without an evaluation harness in place means operating blind: user complaints become the primary signal for model quality degradation, which is both slow and unstructured as a feedback mechanism.
Useful observability infrastructure for AI SaaS includes: structured input-output logging with session and request identifiers, an automated evaluation pipeline that scores sampled outputs against a reference dataset on a scheduled cadence, alerting on output distribution drift (not just infrastructure metrics), and a human review queue for low-confidence or flagged outputs. Teams building on top of AI workflow automation pipelines need this layer to be operational before the first user session, not after the first production incident.
Deployment Architecture for AI SaaS: When to Use Serverless and When Not To
Serverless compute is an attractive default for AI SaaS deployments because it eliminates infrastructure management overhead and scales to zero between requests. For many AI SaaS workloads, however, serverless introduces a latency penalty – cold start time – that compounds with the already-substantial inference latency of frontier model API calls. A serverless function with a 2-second cold start sitting in front of a 3-second inference call produces a 5-second minimum response time for the first request in a session, which is not acceptable for most user-facing AI features.
The engineering decision is not serverless versus containerized – it is which workloads belong on which compute model. Stateless preprocessing tasks, webhook handlers, and background evaluation jobs are good serverless candidates. Streaming inference proxies, multi-step orchestration workflows, and long-running agent sessions are better served by persistent, pre-warmed containers. Most production AI SaaS products need both, deployed as a hybrid, with the boundary between them defined by latency sensitivity and state requirements rather than by a blanket infrastructure preference. This is the kind of architectural tradeoff that surfaces during SaaS platform development design reviews – and the teams that define it explicitly before deployment avoid the cold-start latency surprises that become very visible in user research sessions.
What We’ve Observed Building AI SaaS Products Across California’s Healthcare and Fintech Markets
Across the AI SaaS builds our engineering team has worked on in San Diego, Los Angeles, and San Francisco – spanning clinical documentation tools, financial analysis platforms, and workflow automation products – a consistent pattern emerges. The teams that reach production with the fewest architectural rewrites are the ones that defined their feedback loop infrastructure and their token budget constraints before they wrote their first prompt. Not after. Not when the billing dashboard became alarming. Before.
The most common rewrite we observe is not a model swap. It is a data pipeline redesign triggered by a retrieval quality problem that was architecturally determined from the start. A team builds a retrieval layer that works acceptably in development, where the corpus is small, the queries are controlled, and the latency is not representative. They deploy to production, the corpus grows, query diversity increases, and retrieval precision degrades. The fix requires rebuilding the chunking strategy, re-embedding the entire corpus, and redesigning the re-ranking logic. That work takes weeks in production and affects users while it is happening.
The lesson is not that RAG is fragile. It is that RAG quality is an architecture decision, not a configuration one. Teams that invest in AI readiness assessment before beginning the build surface these design constraints before they become production incidents. That pattern, more than any specific technology choice, is what distinguishes AI SaaS products that scale cleanly from the ones that accumulate technical debt with every new user cohort.
Conclusion
The AI SaaS products that succeed in 2026 will not be defined by which LLM they selected. They will be defined by how precisely their engineering teams understood the orchestration layer, the data pipeline architecture, the inference cost structure, and the feedback loop design before writing the first line of application code. These are not advanced topics reserved for large engineering organizations. They are foundational decisions that every team building an AI SaaS product will face, and the order in which they are made determines whether the product improves continuously or stalls at its initial capability ceiling.
If you are in the early design phase of an AI SaaS product – or if you are already in production and sensing that the architecture decisions made at launch are beginning to constrain what the product can become – the right moment to address them is now, before user growth makes the cost of architectural change steeper. Our engineering team has helped organizations across software development in San Diego and beyond move from early prototype to scalable production architecture with the feedback loops and cost controls in place from the start.
Frequently Asked Questions (FAQs)
What is AI SaaS product development?
AI SaaS product development is the process of designing, building, and deploying a software-as-a-service application in which AI capabilities typically large language models, machine learning models, or both are core to the product’s value rather than supplementary features. Unlike traditional SaaS development, AI SaaS requires managing additional architectural layers including orchestration, retrieval infrastructure, inference routing, and feedback loops that continuously improve model performance over time.
What is the difference between an AI-native SaaS product and a SaaS product with AI features?
An AI-native SaaS product is one where the AI capability is structurally embedded in the product’s core workflow the product cannot function without it. A SaaS product with AI features adds AI capabilities on top of an existing application logic layer, typically as an enhancement rather than as the primary value delivery mechanism. The distinction matters architecturally because AI-native products require the full orchestration and data pipeline stack described in this article, while feature-level AI additions can often be implemented with a simpler API integration. The engineering investment required and the unit economics that result are significantly different between the two approaches.
How do you manage inference costs in an AI SaaS product as it scales?
Inference cost management in AI SaaS is primarily a routing and context design problem, not a model selection problem. The most effective approach uses tiered inference routing: simple tasks such as classification, extraction, or intent detection are routed to smaller, cheaper models, while complex generation or reasoning tasks route to frontier models. Alongside routing, engineering a strict token budget per request type enforced at the orchestration layer prevents the context window bloat that accounts for the majority of runaway inference costs in production AI SaaS deployments.
How are AI SaaS companies in San Francisco and San Diego approaching multi-tenancy?
AI SaaS teams in San Francisco and San Diego operating in regulated verticals such as healthcare and fintech are treating vector store namespace isolation as a primary architecture requirement, not a post-launch security concern. The standard approach partitions the embedding index by tenant at ingestion time, enforces tenant-scoped retrieval queries at the orchestration layer, and treats fine-tuned model weights as tenant-specific artifacts rather than shared infrastructure. Teams in these markets are also designing explicit data boundary contracts between the AI layer and the application layer early in the build, which avoids the cross-tenant data isolation issues that commonly emerge when multi-tenancy is retrofitted after the initial architecture is in place.
Is building a custom AI SaaS product worth the complexity compared to using an off-the-shelf AI tool?
Custom AI SaaS development is worth the complexity when the product’s differentiation depends on domain-specific data, proprietary workflows, or a feedback loop that accumulates a dataset unique to the organization’s users none of which an off-the-shelf AI tool can provide. Off-the-shelf AI tools are appropriate when the use case is generic, and the organization’s competitive advantage does not depend on the AI behavior itself. The decision point is data: if the organization’s proprietary data is what makes the AI output valuable, a custom product architecture is the only way to build that data into the model’s behavior and prevent competitors from replicating the capability by subscribing to the same third-party tool.