
Key Takeaways
- In 2026, building custom APIs on AWS requires deliberate choices around runtime, hosting paradigm, and observability — not just deploying code to the cloud.
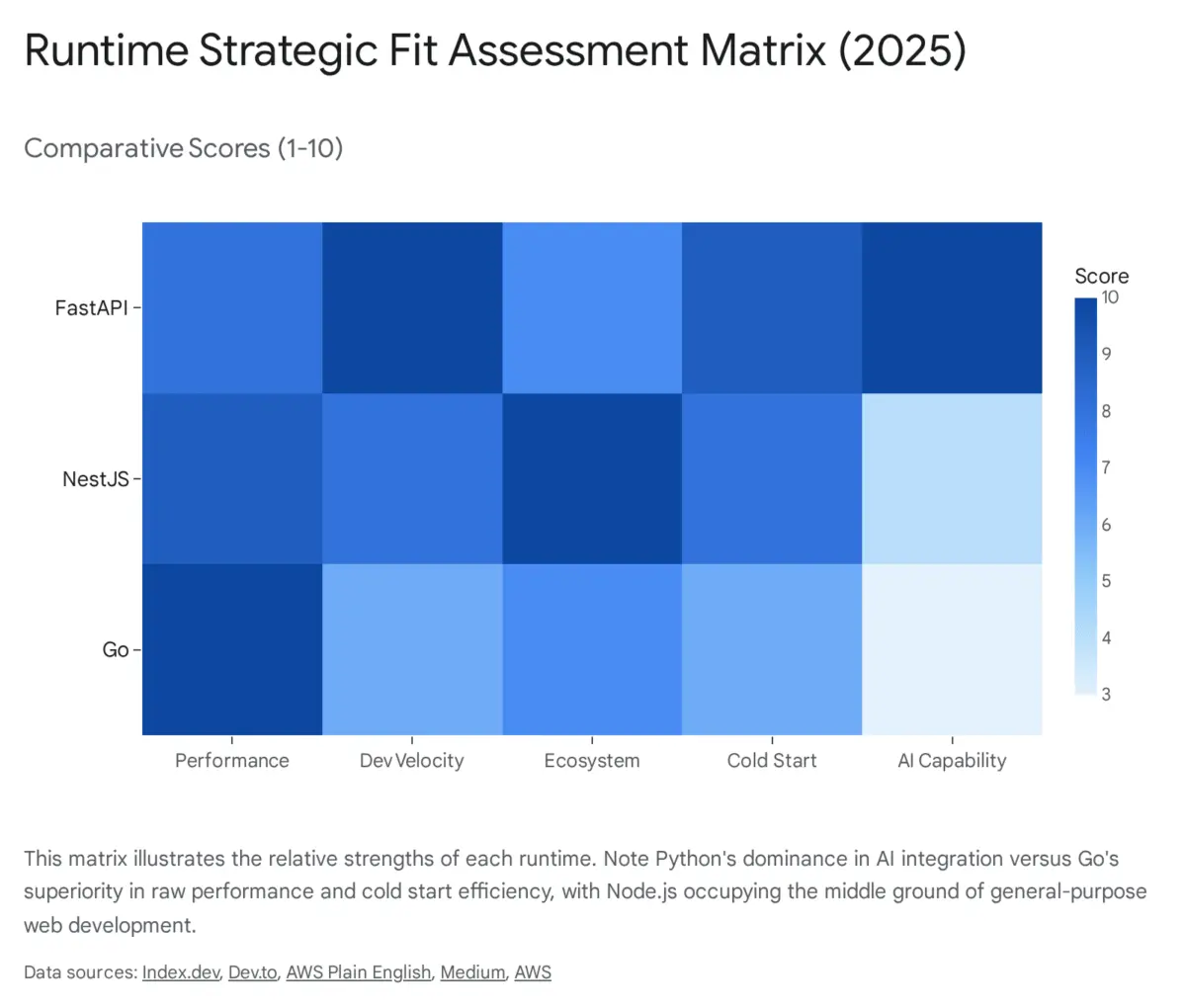
- Node.js with NestJS suits enterprise teams with large JavaScript talent pools; FastAPI excels for AI-integrated services; Go delivers superior cold-start performance and throughput.
- AWS Lambda SnapStart for Python 3.12+ has effectively resolved cold-start penalties for Python workloads, changing the cost calculus for data-heavy APIs.
- For healthcare, fintech, and non-profit platforms serving California and New York markets, the Lambda-vs-Fargate break-even threshold typically falls between 10 and 50 million requests per month.
- AWS has deprecated proprietary X-Ray SDKs in favor of OpenTelemetry, making vendor-neutral observability a baseline requirement for new projects.
Introduction
By 2026, building custom APIs on AWS has evolved far beyond selecting a framework and pushing code to the cloud. According to AWS Compute Blog, the number of Lambda function invocations has grown by over 300% since 2021, yet teams are simultaneously pulling back from microservice sprawl in favor of modular, cost-efficient architectures. The result is a backend landscape that demands genuine architectural strategy, not just cloud familiarity.
The decisions engineers make today about runtime selection, cold-start optimization, and compute hosting directly determine application performance, developer velocity, and long-term operational cost. This guide walks through the full decision matrix: choosing between Node.js with NestJS, Python with FastAPI, and Go; selecting the right hosting paradigm between AWS Lambda and AWS Fargate; and applying cloud-native principles that align with AWS’s current ecosystem. Whether your team is building AI-powered healthcare platforms, high-throughput fintech services, or scalable non-profit applications, the architectural choices covered here are foundational to getting it right.
What Does “Cloud-Native” Actually Mean in 2026?
The term cloud-native has been overused to the point of near-meaninglessness, but in the AWS context of 2026, it has a precise technical definition rooted in the original 12-Factor App methodology. Originally developed by Heroku engineers, the 12-Factor framework prescribes how applications should handle configuration, dependencies, processes, and disposability. In the AWS era, each of these factors maps directly to specific managed services and architectural patterns.
Dependency Isolation
Each runtime handles this factor differently, and the difference matters for cold-start performance. Node.js applications using NestJS carry a substantial node_modules tree; best practice in 2026 is to bundle the entire application into a single JavaScript file using esbuild or SWC, eliminating dead code before deployment. Python introduces binary C-extensions (such as those in NumPy or Pydantic) that must be compiled against the specific AWS runtime architecture, typically Amazon Linux 2023 on Graviton2. Go sidesteps this entirely: its dependency model compiles to a single static binary with no external runtime dependencies, a natural alignment with serverless constraints.
Configuration Separation
Hardcoded configuration is a cardinal sin in any cloud-native deployment. The AWS-native answer is AWS Systems Manager Parameter Store for non-sensitive values and AWS Secrets Manager for credentials and API tokens. For high-volume Lambda functions where runtime retrieval adds latency, the AWS Parameters and Secrets Lambda Extension caches these values inside the execution environment, eliminating repeated API calls on each invocation.
Statelessness and Disposability
Fargate Spot instances and Lambda execution environments can be replaced or terminated at any time. Any state that must persist, whether session data, user context, or transaction history, must be externalized. Amazon ElastiCache (Redis) handles transient session state, while DynamoDB covers durable key-value lookups. Sticky sessions are an anti-pattern in this model and a common source of production incidents for teams migrating from traditional server architectures.
Runtime Comparison: Node.js, Python FastAPI, and Go
No single runtime wins across all dimensions. The right choice depends on team composition, workload characteristics, and where the application sits on the performance-velocity trade-off spectrum.
Node.js with NestJS
NestJS brings Angular-inspired structure to the Node.js backend: strict module organization, TypeScript by default, and a dependency injection system that enforces consistency across large teams. The npm ecosystem remains the largest in the world, and the talent pool for JavaScript and TypeScript developers is deep. For enterprise web applications or Backend-for-Frontend (BFF) layers, NestJS is a defensible choice.
The cost of that structure is startup weight. NestJS performs extensive reflection and module scanning at initialization, producing cold-start latency of 2 to 4 seconds on Lambda without optimization. As of August 2025, AWS charges for the Lambda initialization phase, meaning a heavy NestJS bootstrap now has a direct billing impact, not just a user experience one. The mitigation is aggressive bundling and lazy-loading of modules not needed for the initial request. For consistently high-traffic APIs, deploying NestJS on Fargate eliminates cold starts entirely and is generally the preferred pattern.
Python with FastAPI
FastAPI has become the dominant Python framework for modern API development, built on Starlette for routing and Pydantic for data validation. Its automatic OpenAPI documentation generation is a significant productivity advantage, and its full embrace of async/await makes it efficient for I/O-bound microservices. Most importantly, Python is the language of AI and data science. Teams building APIs that integrate PyTorch, TensorFlow, LangChain, or Pandas avoid an impedance mismatch that would otherwise require a bridge between languages.
The transformative development for Python on AWS is Lambda SnapStart, now available for Python 3.12 and later. SnapStart initializes the function once, snapshots the memory state, and reuses that snapshot for subsequent cold invocations. What was previously a 2 to 4 second cold-start penalty for heavy Python workloads (due to loading Boto3, Pandas, or similar libraries) now resolves in under 500 milliseconds. This fundamentally changes the Lambda-vs-Fargate calculus for Python-based APIs.
Go
Go was designed at Google for networked, distributed systems, and it shows. A Go binary starts in under 100 milliseconds on AWS Lambda’s provided.al2023 runtime. Its goroutine concurrency model allows a single process to handle tens of thousands of simultaneous connections with minimal memory overhead, outperforming Node.js’s single-threaded event loop and Python’s GIL-constrained concurrency for CPU-intensive or mixed workloads. The static binary eliminates dependency headaches at deployment time.
The trade-offs are real. Go has no all-in-one framework comparable to NestJS or Django. Dependency injection, ORMs, and routing require explicit wiring, producing more verbose code. The developer market for experienced Go engineers is smaller than for Node.js or Python, and compensation expectations are higher. For teams building high-throughput infrastructure services, payment processors, or real-time data pipelines, Go’s performance characteristics justify the investment. For rapid prototyping or data-centric applications, the Python ecosystem typically wins on developer velocity.
AWS Lambda vs. AWS Fargate: Choosing the Right Compute Paradigm
Runtime selection and hosting paradigm are independent decisions, but they interact in ways that significantly affect cost and performance.
When Lambda Makes Sense
Lambda remains the strongest choice for event-driven workloads: S3 upload processors, SQS consumers, scheduled jobs, and APIs with genuinely sporadic traffic. Its billing model (duration in gigabyte-seconds) means you pay nothing when the function is idle, a meaningful advantage for applications with uneven or unpredictable load patterns.
The August 2025 change to Lambda billing, which now includes the initialization phase, raises the cost of poorly optimized functions. A NestJS function with a 5-second cold start accrues billing during that initialization window even before processing a single request. Teams deploying Lambda in 2026 should treat cold-start optimization as a first-order concern, not a nice-to-have.
When Fargate Is the Better Fit
Fargate removes EC2 cluster management while providing container-level control. It is the natural home for long-running services, WebSocket connections, background threads, and APIs with sustained high throughput. Fargate billing is based on vCPU and memory per hour, making it more predictable than Lambda for steady-state workloads.
The break-even point between Lambda and Fargate typically falls between 10 and 50 million requests per month, depending on average execution duration. A single Fargate task (1 vCPU, 2 GB RAM) running a Go or Node.js service can handle hundreds of concurrent requests through its concurrency model, whereas Lambda would spin up hundreds of separate execution environments, each billing independently.
The NAT Gateway Tax
A frequently overlooked cost factor in Fargate deployments is NAT Gateway charges. Security best practices require Fargate tasks to run in private subnets, but those tasks still need to reach Amazon ECR to pull images and communicate with external APIs. That traffic routes through a NAT Gateway, which charges both an hourly fee and a data processing fee of $0.045 per GB.
The mitigation is VPC Endpoints (PrivateLink). A Gateway Endpoint for S3 (which stores ECR image layers) is free and eliminates the largest portion of NAT traffic. An Interface Endpoint for the ECR API keeps image pull requests on the AWS private network. Teams that skip this configuration often discover their networking bill exceeds compute costs after the first month of heavy deployment activity.

Advanced Networking: API Gateway vs. Application Load Balancer
The ingress layer for a custom API is not a neutral choice. Amazon API Gateway and the Application Load Balancer (ALB) serve different use cases, and the cost differential at scale is substantial.
API Gateway’s REST API product charges $3.50 per million requests; the HTTP API variant is $1.00 per million. It offers advanced features — API keys, usage plans, request validation, and direct AWS service integrations — that make it compelling for externally published APIs or developer platforms. Its soft limit of 10,000 requests per second per region can become a constraint for hyper-scale applications, though this is raisable via AWS Support.
The ALB operates at Layer 7 and bills on Load Balancer Capacity Units. For high-throughput applications, ALB is frequently 10 times cheaper than API Gateway and scales to millions of requests per second without configuration changes. It is the natural partner for Fargate-based services and handles path-based routing to multiple target groups cleanly.
One capability that shifted the calculus for AI-oriented APIs in 2025 is Lambda Response Streaming via Function URLs. Streaming token output from large language models requires the API layer to pass data through without buffering the full response. API Gateway supports this pattern; ALB has historically buffered responses, which elevates Time-To-First-Byte (TTFB) in generative AI applications. Teams building LLM-backed services on Lambda should factor this into their ingress design.
Observability: OpenTelemetry Replaces Proprietary AWS SDKs
One of the most consequential shifts in AWS observability during 2025 was the formal deprecation of the proprietary AWS X-Ray SDKs. AWS now recommends the AWS Distro for OpenTelemetry (ADOT) as the standard for all new tracing and metrics instrumentation.
ADOT runs as a sidecar collector in Fargate or as a Lambda Layer. It captures traces from application code instrumented with standard OpenTelemetry libraries and forwards them to AWS X-Ray and CloudWatch. The architectural benefit extends beyond AWS: because the instrumentation is vendor-neutral, migrating from X-Ray to Datadog, Honeycomb, or Grafana Tempo requires only a configuration change in the OTel collector, not a code rewrite across every service. For engineering teams managing a portfolio of applications, this eliminates one of the most painful forms of vendor lock-in in distributed systems.
Event-Driven Integration: Decoupling for Resilience
Synchronous HTTP calls between services couple availability directly. When Service A calls Service B synchronously, any latency spike or failure in Service B propagates immediately to Service A. Cloud-native APIs on AWS use asynchronous messaging to break this dependency.
Amazon SQS implements the Queue-Based Load Leveling pattern: the API writes requests to a queue, and a downstream worker (Lambda or Fargate) processes them at a controlled rate. This prevents traffic spikes from overwhelming databases or third-party dependencies. Amazon EventBridge adds content-based routing on top of fan-out: an API can emit a single event, and EventBridge routes it to different targets based on payload values, allowing business logic to evolve without touching the emitting service.
For healthcare and fintech applications, this pattern is particularly valuable. A patient intake API can write to an SQS queue and return a 202 Accepted immediately, while downstream services process eligibility checks, notifications, and record creation asynchronously. The user-facing latency stays low regardless of backend processing time. Teams building on healthcare software platforms or fintech services see consistent gains from this decoupling approach.
The Modular Monolith: A Pragmatic Return to Simplicity
The microservices movement produced genuinely useful patterns, but it also produced distributed transaction nightmares, excessive service-to-service latency, and DevOps overhead that dwarfed actual feature development. By 2026, a clear counter-pattern has emerged: the modular monolith.
A modular monolith is a single deployment unit (one Fargate service or a cohesive set of Lambda functions) where the internal code is organized into strictly isolated modules with defined interfaces. An e-commerce backend might have an OrderModule and a UserModule that share a database but communicate only through typed interfaces. Internal method calls operate at nanosecond latency. The entire application runs on a single laptop for development. Shared Fargate resources cost less than running 10 separate idle containers.
AWS App Runner and Fargate both support this pattern cleanly. The pragmatic approach for most teams in 2026: start with a modular monolith, keep module boundaries clean, and extract individual services to Lambda only when a specific module creates a measurable bottleneck. Scale creates the need for distribution; distribution should not be the starting assumption.
Our Perspective
The teams we work with at Bitcot, building production applications across healthcare technology, fintech, and non-profit platforms, face a version of this decision on nearly every engagement. What we observe consistently is that the runtime choice matters less than the architecture around it. A well-structured FastAPI service on Lambda with SnapStart enabled routinely outperforms a poorly bundled NestJS application on Fargate. The configuration, observability, and networking layers are where most production issues originate, not the language.
For applications serving California and New York markets where uptime expectations are high and traffic patterns often spike around business hours, the Fargate model with ALB ingress provides the most predictable operational profile. For event-driven workloads common in healthcare data pipelines or non-profit case management systems, Lambda with SQS decoupling remains a cost-efficient and resilient pattern. The right answer is almost always a hybrid, with the routing layer determining which compute target handles which request type. Our custom software development practice grounds these decisions in the specific traffic and team constraints of each engagement.

Conclusion
Building custom APIs on AWS in 2026 rewards deliberate architectural thinking. The runtime selection (NestJS for enterprise structure, FastAPI for AI-centric services, Go for high-throughput systems) sets the performance ceiling and operational floor for everything that follows. The hosting choice (Lambda for event-driven and sporadic workloads, Fargate for sustained throughput) determines the cost curve at scale. And the observability layer, now standardized on OpenTelemetry, determines how quickly your team identifies and resolves issues in production.
None of these decisions exist in isolation. The most successful API architectures in the current AWS ecosystem treat language, compute, networking, and observability as a coherent system, not a collection of independent choices. If your team is navigating these trade-offs for a platform that needs to scale reliably, the right next step is a focused architectural conversation before the first line of code is written.
Frequently Asked Questions
When should I choose AWS Lambda over Fargate for a custom API?
Lambda is the better fit when your API handles sporadic or event-driven traffic, processes messages from SQS or S3, or has significant idle time between requests. The pay-per-invocation model means you incur no cost during quiet periods. Fargate becomes more cost-effective when your API sustains more than 10 to 50 million requests per month, runs long-lived WebSocket connections, or requires persistent background threads that do not align with Lambda’s execution model.
Has Python's cold-start problem on AWS Lambda been solved in 2026?
Largely, yes. Lambda SnapStart, now available for Python 3.12 and later runtimes, initializes the function once, snapshots the memory state including loaded libraries, and restores from that snapshot on subsequent cold invocations. What previously produced 2 to 4 second cold-start penalties for Python functions loading heavy libraries now resolves in under 500 milliseconds. For teams building FastAPI services on Lambda, enabling SnapStart is a straightforward configuration change with significant performance impact.
What is the practical difference between API Gateway and an Application Load Balancer for API ingress on AWS?
API Gateway offers rich features (API keys, usage plans, direct AWS service integrations) and is well-suited for externally published APIs with moderate traffic. However, it charges per request, which becomes expensive at scale. The Application Load Balancer bills on capacity units rather than individual requests, making it significantly cheaper for high-throughput APIs (often 10 times less expensive) and capable of handling millions of requests per second without raising limits. Fargate-based APIs almost always use ALB; Lambda-based APIs use API Gateway for feature-rich external APIs or ALB when cost at scale is the priority.
Why is OpenTelemetry replacing the AWS X-Ray SDK in new projects?
AWS deprecated the proprietary X-Ray SDK in favor of the AWS Distro for OpenTelemetry (ADOT) because OpenTelemetry is a vendor-neutral standard. Instrumenting application code with OTel libraries means the tracing pipeline is not tied to AWS: switching from X-Ray to Datadog, Honeycomb, or another observability backend requires only a configuration change in the OTel collector, not code modifications across every service. For teams managing multi-cloud deployments or expecting to evolve their observability tooling, this separation of instrumentation from backend is a meaningful long-term advantage.











