If you’re not automating data extraction in 2025, you’re already behind.
Data is the new oil, but extracting it from websites shouldn’t feel like drilling through bedrock. In today’s fast-paced digital world, businesses are overwhelmed with web-based information, yet many still struggle to put it to use effectively.
If you’re a CEO, startup founder, or entrepreneur, you’ve likely faced the frustration of manual data collection or scraping tools that are slow, unreliable, or simply not built to scale.
At the same time, your competitors, including Fortune 500 companies, are already using advanced automated web scraping tools to gain real-time market insights, track pricing, monitor competition, and extract leads at scale. Relying on outdated methods can cost you valuable time, money, and growth opportunities.
This is where web scraping automation becomes a game-changer.
As an AI-powered web and app development company, we’ve seen how the right scraping tools can reshape the way businesses collect and use data. In this guide, we’ll walk you through the best automated web scraping tools and software for 2025, organized by use case and complexity level.
What Are Automated Web Scraping Tools and Why Do You Need Them?
Automated web scraping tools are software solutions designed to extract data from websites without manual intervention. These tools can navigate web pages, parse HTML content, handle JavaScript rendering, and export data in structured formats like CSV, JSON, or directly to databases.
In 2025, the demand for automated data extraction has exploded. The best web scraping tools in 2025 cater to a wide range of users, from non-technical beginners to advanced developers. No-code platforms like ParseHub and Octoparse simplify data collection, while tools like Scrapy and Bright Data provide powerful customization for enterprise-level projects.
Why businesses need automated web scraping:
- Time Efficiency: Automating data collection saves thousands of hours compared to manual extraction
- Scale: Process hundreds of websites simultaneously instead of one at a time
- Accuracy: Reduce human errors in data collection and formatting
- Real-time Insights: Get up-to-date information for competitive analysis and market research
- Cost Reduction: Eliminate the need for large data entry teams
How to Choose the Right Web Scraping Tool for Your Business
Selecting the best web scraping tool depends on several critical factors:
- Technical Expertise Level: Are you a developer comfortable with code, or do you need a no-code solution? Your technical skills will determine whether you need visual scraping tools or can handle API-based solutions.
- Scale Requirements: How much data do you need to extract? Enterprise-level operations require different tools than small-scale projects.
- Budget Constraints: Tools range from free open-source options to enterprise solutions costing thousands monthly.
- Compliance Needs: Different tools offer varying levels of ethical scraping features like rate limiting and robots.txt compliance.
- Data Complexity: Simple text extraction requires different tools than complex JavaScript-heavy sites or real-time data extraction.
Best No-Code Automated Web Scraping Tools
1. Octoparse
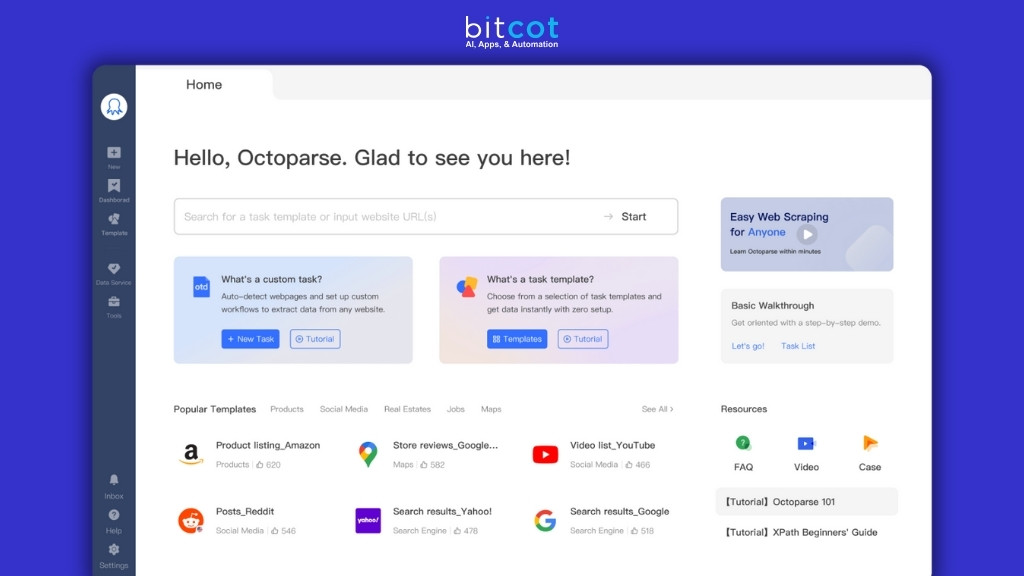
User-friendly visual web scraping tool with point-and-click interface. Extract data from any website without coding through intuitive workflow builder and automated scheduling capabilities.
Key Features:
- Visual workflow builder
- Cloud-based scraping
- Automatic data export to multiple formats
- Built-in proxy rotation
- Scheduled scraping tasks
Best For: Small to medium businesses, marketers, and researchers who need regular data extraction without technical complexity.
Pricing: Free plan available, paid plans start at $75/month
2. ParseHub
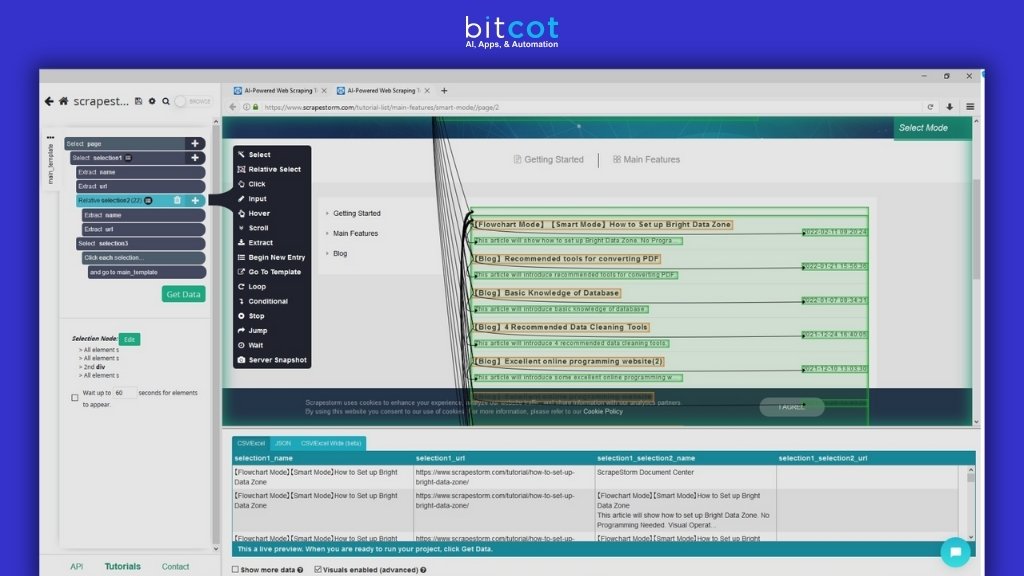
Handles complex websites with dynamic content using machine learning. Adapts automatically to website changes while providing powerful real-time data extraction capabilities.
Key Features:
- Handles JavaScript-heavy sites
- Automatic IP rotation
- RESTful API access
- Webhook support
- Real-time data extraction
Best For: E-commerce businesses tracking competitor pricing, real estate professionals, and content aggregators.
Pricing: Free plan for 5 projects, paid plans start at $149/month
3. Apify
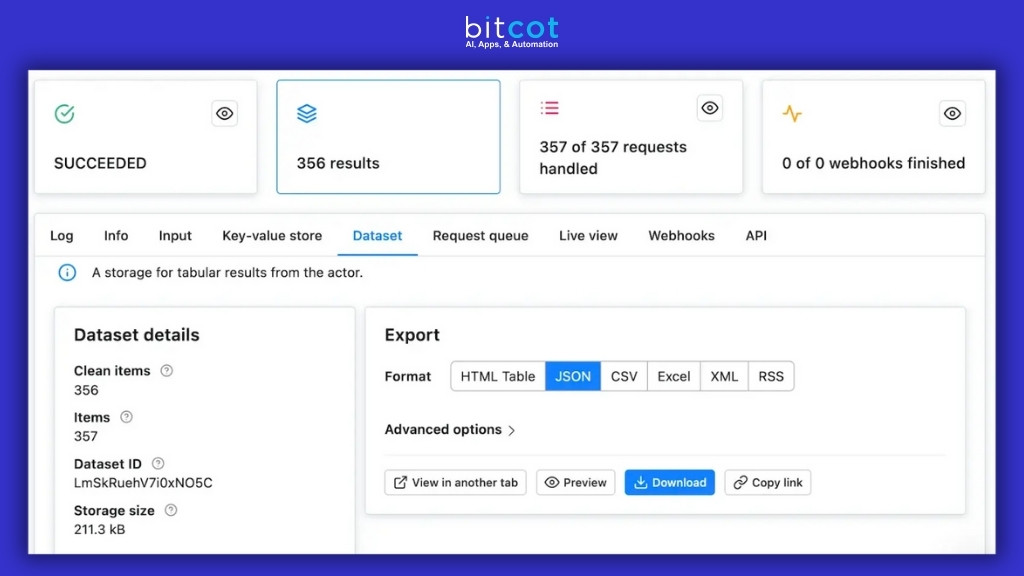
Cloud platform offering 5,000+ ready-made scrapers with both no-code and developer-friendly solutions. Serverless architecture with AI-powered data extraction and extensive integrations.
Key Features:
- 5,000+ pre-built scrapers
- Serverless architecture
- AI-powered data extraction
- Extensive integration options
- Custom development services
Best For: Growing businesses that need both simple and complex scraping solutions.
Pricing: Pay-as-you-go model, starting at $49/month
4. Mozenda
Professional-grade web scraping platform with no-code interface. Features advanced data cleaning tools, cloud-based storage, and automated publishing for scalable data extraction.
Key Features:
- Point-and-click interface
- Advanced data cleaning tools
- Cloud-based storage
- Automated publishing options
- Team collaboration features
Best For: Businesses requiring regular data extraction with built-in data processing capabilities.
Pricing: Free trial available, paid plans start at $99/month
Best API-Based Automated Web Scraping Tools
1. ScrapingBee
Web scraping API handling technical complexities like JavaScript rendering, proxy management, and CAPTCHA solving. Offers AI-powered data extraction with multi-language support.
Key Features:
- JavaScript rendering
- Proxy management
- CAPTCHA solving
- Screenshot capabilities
- Multiple programming language support
Best For: Developers and tech teams needing reliable API-based scraping solutions.
Pricing: Free plan available, paid plans start at $99/month
2. Bright Data (formerly Luminati)

Enterprise-grade web scraping with world’s largest proxy network. Features advanced AI capabilities, compliance tools, and real-time data collection for large-scale operations.
Key Features:
- World’s largest proxy network
- Advanced AI capabilities
- Compliance tools
- Real-time data collection
- Enterprise-grade security
Best For: Large enterprises, data intelligence companies, and high-volume operations.
Pricing: Custom pricing based on usage and requirements
3. Oxylabs
Enterprise-grade web scraping with comprehensive proxy infrastructure. Features advanced proxy rotation, real-time extraction, machine learning-powered scraping, and dedicated support.
Key Features:
- Advanced proxy rotation
- Real-time data extraction
- Machine learning-powered scraping
- Global proxy network
- Dedicated support team
Best For: Enterprise clients requiring high-volume, reliable data extraction with premium support.
Pricing: Custom enterprise pricing starting at $300/month
Best Enterprise Automated Web Scraping Solutions
1. Zyte (formerly Scrapinghub)
Comprehensive web scraping services with managed solutions for enterprise clients. Offers custom development, smart proxy management, advanced analytics, and compliance consultation.
Key Features:
- Managed scraping services
- Custom development
- Smart proxy management
- Advanced analytics
- Compliance consultation
Best For: Large enterprises needing fully managed scraping solutions.
Pricing: Custom enterprise pricing
2. Diffbot
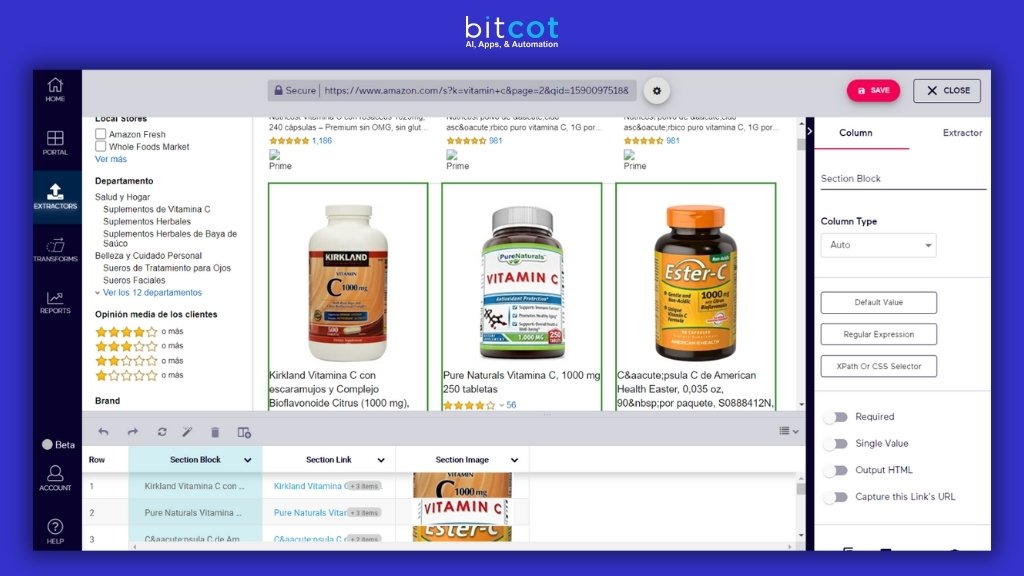
AI-powered platform automatically extracting structured data from web pages. Features real-time processing, knowledge graph creation, and custom AI training for intelligent content analysis.
Key Features:
- AI-powered extraction
- Automatic data structuring
- Real-time processing
- Knowledge graph creation
- Custom AI training
Best For: Media companies, research organizations, and content aggregators.
Pricing: Custom pricing based on usage
3. Import.io

Comprehensive data extraction platform with visual extraction tools, API integration, data quality monitoring, compliance tools, and professional services for reliable enterprise solutions.
Key Features:
- Visual data extraction
- API integration
- Data quality monitoring
- Compliance tools
- Professional services
Best For: Mid to large enterprises needing reliable data extraction with support.
Pricing: Custom enterprise pricing
4. PromptCloud
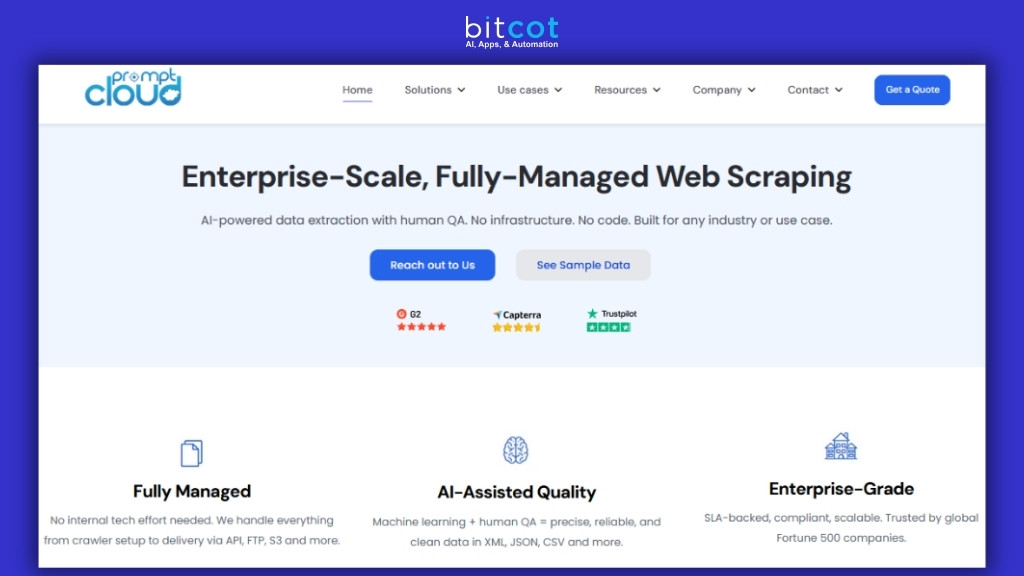
Managed web scraping services focusing on large-scale data extraction. Handles entire scraping infrastructure while providing clean, structured data with quality assurance processes.
Key Features:
- Fully managed service
- Large-scale data processing
- Custom data formats
- Quality assurance processes
- Dedicated account management
Best For: Enterprises needing hands-off data extraction with guaranteed quality and compliance.
Pricing: Custom pricing based on data volume and complexity
Best AI-Powered Automated Web Scraping Tools
1. Browse AI
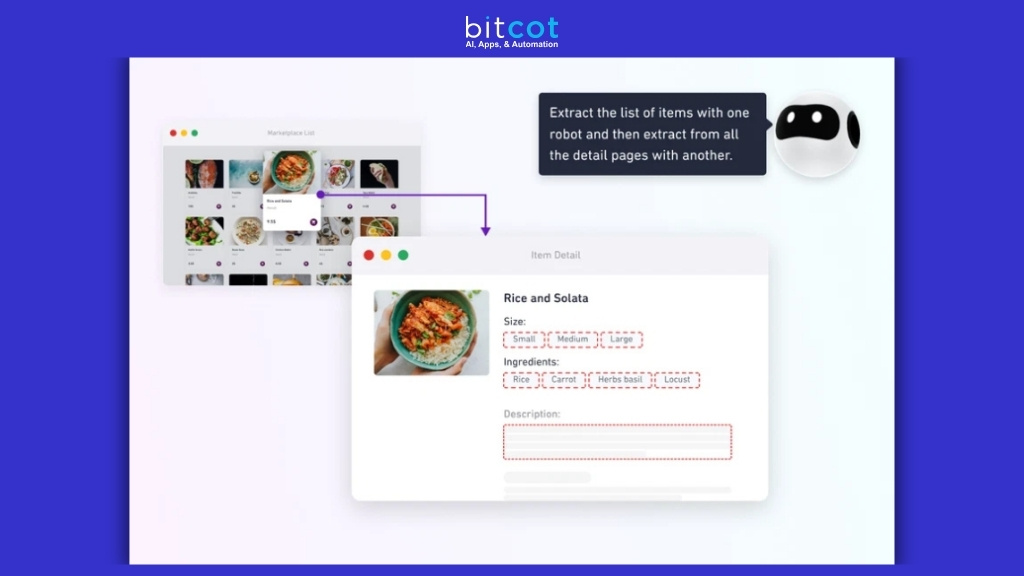
AI-powered website scraping platform enabling data extraction without coding. Uses machine learning to automatically adapt to website changes with real-time monitoring capabilities.
Key Features:
- AI-powered data extraction
- Automatic adaptation to site changes
- No-code interface
- Real-time monitoring
- Custom robots creation
Best For: Businesses needing adaptive scraping solutions that can handle dynamic websites.
Pricing: Free plan available, paid plans start at $49/month
2. Scrapfly
Combines traditional scraping with AI-powered features for complex extraction scenarios. Features CAPTCHA solving, proxy rotation, JavaScript rendering, and anti-detection measures.
Key Features:
- AI-powered CAPTCHA solving
- Automatic proxy rotation
- JavaScript rendering
- Anti-detection measures
- Real-time data processing
Best For: Businesses dealing with sophisticated anti-scraping measures.
Pricing: Free plan available, paid plans start at $30/month
3. Firecrawl

Comprehensive AI-powered web scraping solution with exceptional developer recognition. Features intelligent content extraction, automatic data structuring, and natural language processing capabilities.
Key Features:
- AI-powered content extraction
- Automatic data structuring
- Natural language processing
- Multi-format output support
- Advanced crawling algorithms
Best For: Developers and businesses requiring intelligent data extraction with minimal configuration.
Pricing: Free tier available, paid plans start at $20/month
Best Manual Web Scraping Tools
1. Scrapy (Python Framework)
Open-source Python framework designed for large-scale web scraping projects. Built for speed and efficiency with comprehensive features for handling complex scraping scenarios.
Key Features:
- Fast and powerful Python framework
- Built-in support for handling requests and responses
- Automatic throttling and concurrent processing
- Extensive middleware support
- Built-in data export capabilities
- Strong community and extensive documentation
Best For: Python developers building custom scraping solutions that need high performance and scalability.
Pricing: Free and open-source
2. Beautiful Soup (Python)
Python library for easy web page data extraction. Offers simple integration, powerful parsing capabilities, extensive documentation, and flexible data extraction for developers.
Key Features:
- Simple Python integration
- Powerful parsing capabilities
- Extensive documentation
- Active community support
- Flexible data extraction
Best For: Python developers and data scientists learning web scraping.
Pricing: Free and open-source
3. Selenium WebDriver
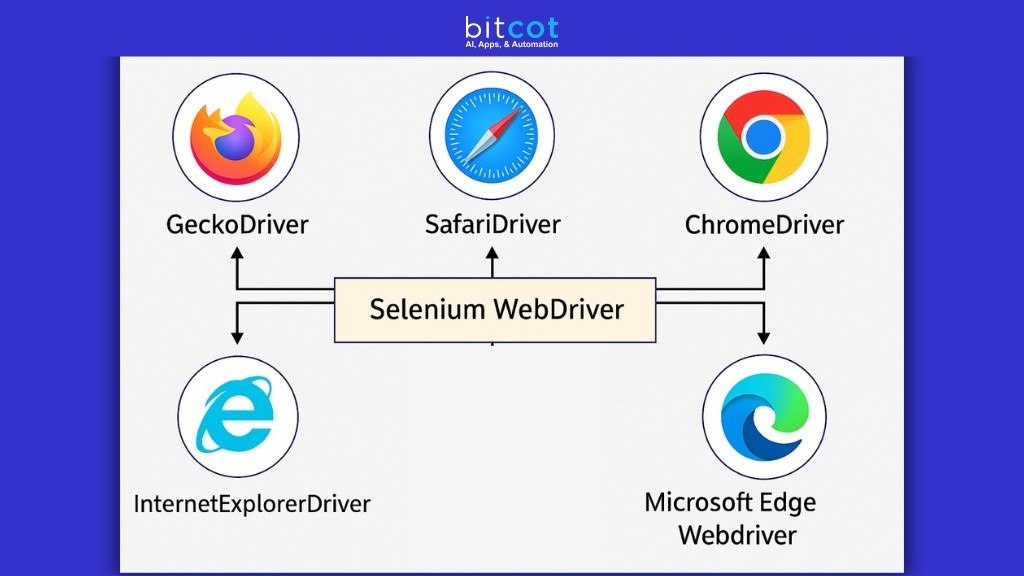
Web browser automation tool for JavaScript-heavy site scraping. Supports multiple browsers, complex interactions, cross-platform compatibility, and extensive programming language support.
Key Features:
- Multiple browser support
- JavaScript execution
- Complex interaction handling
- Cross-platform compatibility
- Extensive language support
Best For: Developers needing to interact with complex web applications.
Pricing: Free and open-source
4. Puppeteer (JavaScript/Node.js)

Node.js library providing high-level API to control Chrome/Chromium browsers. Excellent for scraping JavaScript-heavy websites and generating PDFs or screenshots.
Key Features:
- Full Chrome browser control
- JavaScript execution support
- Screenshot and PDF generation
- Network interception capabilities
- Mobile device emulation
- Automated form submission
Best For: JavaScript developers needing to scrape modern web applications with complex JavaScript interactions.
Pricing: Free and open-source
5. Jupyter Notebooks
Interactive computing environment that combines code execution, data visualization, and documentation. Popular for data science projects including web scraping and analysis.
Key Features:
- Interactive code execution
- Data visualization capabilities
- Markdown documentation support
- Easy sharing and collaboration
- Integration with Python scraping libraries
- Step-by-step analysis workflow
Best For: Data scientists and analysts who need to combine web scraping with data analysis and visualization.
Pricing: Free and open-source
How to Implement Web Scraping in Your Business Strategy
Step 1: Define Your Data Needs Identify what data you need, how often you need it, and what format works best for your team. This will help you choose the right tool and approach.
Step 2: Assess Your Technical Capabilities Determine whether you need a no-code solution or if you have developers who can work with API-based tools. This significantly impacts your tool selection.
Step 3: Start Small and Scale Begin with a pilot project using free or low-cost tools to prove value before investing in enterprise solutions.
Step 4: Ensure Compliance Work with legal teams to ensure your scraping activities comply with website terms of service and relevant regulations.
Step 5: Monitor and Optimize Regularly review your scraping operations for efficiency, accuracy, and compliance. Adjust your approach based on results and changing needs.
Why Partner with an AI Automation Agency
While tools are essential, successful web scraping often requires strategic implementation and ongoing optimization. As an AI automation Agency, we help businesses navigate the complex landscape of data extraction and automation. Our comprehensive Web Scraping Automation Case Study demonstrates how strategic implementation can deliver measurable ROI within 30 days, providing actionable insights for businesses across various industries.
Benefits of professional implementation:
- Custom solution development
- Compliance guidance
- Integration with existing systems
- Ongoing maintenance and optimization
- Strategic data utilization planning
The Future of Web Scraping in 2025 and Beyond
The web scraping landscape continues evolving rapidly. Advanced Automation: Mozenda supports automated scraping workflows, allowing businesses to set up recurring scraping tasks to gather data regularly. This trend toward more sophisticated automation will only accelerate.
Emerging trends include:
- AI-powered adaptive scraping
- Better integration with business intelligence tools
- Enhanced compliance features
- Real-time data processing capabilities
- Improved handling of complex JavaScript applications
The integration of advanced AI Tools with web scraping capabilities is creating new opportunities for businesses to extract insights from web data automatically.
Wrapping Up
Web scraping tools today cater to every business—from startups needing affordable data to enterprises demanding advanced automation. But picking the right tool is just step one. Success lies in smart implementation, ongoing upkeep, and handling challenges like anti-scraping defenses, compliance, and data quality.
Action Steps:
- Review your current data collection process for gaps
- Select 2–3 tools from this guide that suit your goals and budget
- Launch a small pilot to test and validate performance
- Scale what works; consider expert help for complex needs
Why Choose Bitcot for Data Extraction?
Bitcot offers end-to-end data scraping solutions—from strategy to support—ensuring efficient, compliant, and scalable operations.
Our Services:
- Custom scraping solutions tailored to your needs
- Tool selection and ROI-focused implementation
- Compliance and legal guidance
- Data quality control and integration
- 24/7 monitoring and support
Our Edge:
As a leading web data scraping company, we bring:
- Expertise in Scrapy, Selenium, Airflow
- AI-powered extraction for complex use cases
- Automation at scale (RPA, LinkedIn scraping, etc.)
Data-driven growth starts with the right strategy. Let Bitcot help you build a solution that delivers measurable impact. Contact us today to get started.
Frequently Asked Questions
What is the difference between web scraping and web crawling?
Web scraping focuses on extracting specific data from web pages, while web crawling involves systematically browsing websites to discover and index content. Scraping is more targeted and data-focused, whereas crawling is broader and discovery-focused. Most modern tools combine both capabilities to provide comprehensive data extraction solutions.
Is web scraping legal, and how can I ensure compliance?
Web scraping legality depends on various factors including the website’s terms of service, the type of data being extracted, and how it’s used. To ensure compliance, always check robots.txt files, respect rate limits, avoid scraping personal data without consent, and consult legal counsel for commercial use. Many modern scraping tools include built-in compliance features.
How do I handle websites that block web scraping attempts?
Modern websites often employ anti-scraping measures like CAPTCHAs, IP blocking, and JavaScript challenges. To handle these, use tools with built-in proxy rotation, CAPTCHA solving capabilities, and JavaScript rendering. Advanced tools like Bright Data and ScrapingBee specifically address these challenges with sophisticated anti-detection features.
What's the best web scraping tool for beginners with no coding experience?
For complete beginners, visual scraping tools like Octoparse, ParseHub, and Web Scraper Chrome Extension offer the easiest entry point. These tools use point-and-click interfaces and don’t require programming knowledge. Start with free versions to learn the basics before investing in paid features.
How much does professional web scraping cost, and what factors affect pricing?
Web scraping costs vary widely based on volume, complexity, and tool choice. Free tools exist for simple tasks, while enterprise solutions can cost thousands monthly. Key pricing factors include data volume, website complexity, frequency of scraping, proxy usage, and support level. Most tools offer tiered pricing starting from $30-100/month for small businesses, with enterprise solutions requiring custom quotes.