Key Takeaways
- AI diagnostic tools are transforming radiology, pathology, and clinical risk prediction.
- Fewer than 10% of AI diagnostic studies include real-world validation, according to The Lancet Digital Health.
- Algorithmic bias remains a major concern in healthcare AI deployments.
- Successful AI adoption depends heavily on EHR integration and workflow alignment.
- Healthcare organizations should carefully evaluate AI vendors before deployment.
- The US healthcare AI market is projected to reach $43B by 2030.
Introduction
Every year, health systems sign AI diagnostic contracts based on benchmark figures that were never tested in environments like theirs. This guide exists to change that. You will learn exactly which questions expose a weak vendor validation process, why EHR workflow fit matters more than headline accuracy, how algorithmic bias originates and what governance actually prevents it, and what contract terms protect your organization when a deployed model underperforms.
This is a procurement and governance guide for healthcare technology leaders, clinical informaticists, and health system executives who are done exploring and ready to decide.
The Diagnostic AI Decision Your Organization Will Make This Year
Every health system operating today is receiving pitches for AI diagnostic tools. The standard pitch includes compelling accuracy figures drawn from peer-reviewed studies, a polished demonstration running on carefully selected data, and a reference list of early adopters. What that pitch typically does not include is an honest accounting of the conditions under which those results were achieved and how different those conditions may be from the clinical reality your organization operates in every day.
This is not primarily a technology question. The tools exist. The underlying science supporting AI-assisted diagnosis in several specific clinical areas is well-established. The question for any healthcare organization in 2026 is a procurement and governance question: Which tools, deployed in which ways, with which safeguards, will produce durable improvements in clinical outcomes rather than expensive experiments that get quietly shelved when they fail to perform as marketed.
That question deserves a practitioner-level answer, one that treats healthcare technology leaders as decision-makers navigating real operational tradeoffs rather than an audience for technology enthusiasm. That is what this guide is built to provide.
How AI Is Being Used in Medical Diagnosis Right Now
The clinical AI application landscape has matured significantly recently. Rather than discussing theoretical future capabilities, this section covers the categories where live deployments are producing documented operational results today.
Computer Vision in Diagnostic Imaging
The strongest commercial track record in healthcare AI involves analyzing medical images. Radiology departments have deployed machine learning tools that screen large volumes of chest X-rays, prioritize CT findings for time-sensitive review, and sort MRI worklists so that the cases most likely to require urgent clinical attention reach a radiologist faster than they would through sequential queue processing.
The operational value here addresses a specific and well-documented problem: imaging volume is growing faster than the radiologist workforce can absorb it through conventional means. AI triage creates a filter that sorts high-acuity from low-acuity studies before a human reviewer ever opens the first image. That sorting function, not the accuracy of the AI in diagnosing any specific condition, is where much of the day-to-day clinical value is actually generated.
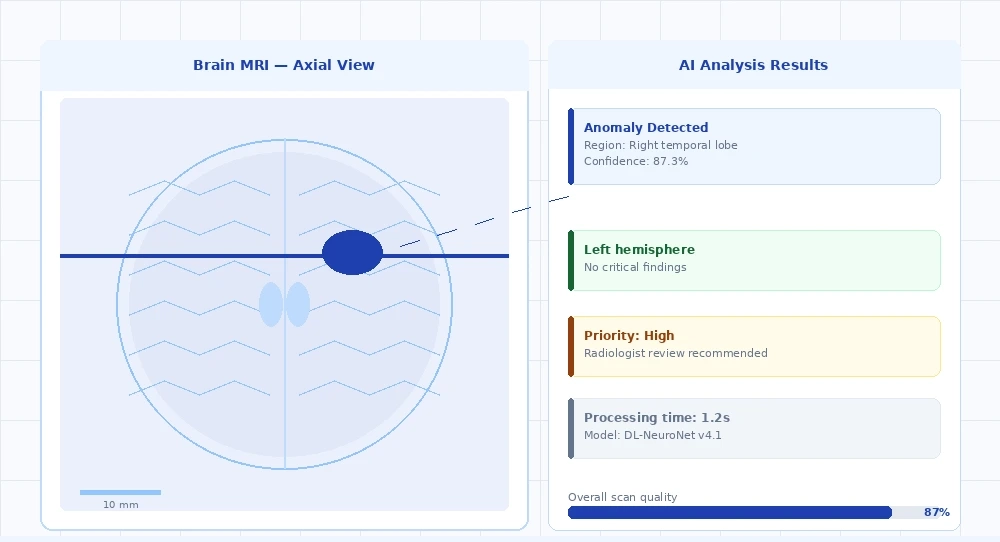
AI-assisted MRI analysis: machine learning triage prioritizes high-acuity findings and surfaces anomaly confidence scores within the existing radiologist workflow.
Tissue and Cell Analysis in Pathology
Computational pathology has moved from specialized research environments into production use at several major cancer centers. Machine learning models trained on digitized slide images are being used to identify cellular features, margins, mitotic activity, and nuclear grade with a degree of consistency that measurably reduces the interpretation variability that has historically existed between individual pathologists examining the same specimen.
The operational argument for computational pathology is built less on speed and more on standardization. Diagnostic variability between pathologists on identical specimens is a well-documented problem in oncology pathology. AI-assisted second reads create a documented, auditable layer of analysis that strengthens the evidentiary basis for treatment decisions and reduces the risk associated with single-reader interpretation on high-stakes cases.
Early Warning and Clinical Risk Stratification
Predictive models embedded within EHR platforms have become one of the most widely deployed categories of clinical AI. These systems continuously analyze and update structured patient data, vital sign trajectories, sequential lab results, and medication order patterns and generate risk alerts for deterioration events, including sepsis onset, acute kidney injury, and rapid clinical decline.
The adoption advantage for EHR-integrated early warning AI relates directly to workflow fit. These systems do not require clinicians to check a separate application or review an external dashboard. The alert surfaces inside the workflow they are already using. That integration removes the primary adoption barrier that has stalled many other categories of healthcare AI: the requirement to add a new step to an already compressed workflow.
Understanding AI Diagnostic Accuracy Beyond the Headline Numbers
Vendor accuracy claims require scrutiny, and the issue is not that vendors are being deceptive. The issue is structural: accuracy measured under controlled research conditions and accuracy experienced in a live clinical environment are fundamentally different measurements, and the gap between them is rarely disclosed upfront in procurement conversations.

Why Research Performance Does Not Predict Operational Performance
The majority of published AI validation studies share a common characteristic: the held-out test set was drawn from the same institution, often from the same time period, as the training data. The model has never been exposed to the variation it will encounter once deployed across multiple sites with different imaging hardware manufacturers, different patient demographics, different clinical documentation practices, and different EHR configurations.
When a model that achieved strong results on a homogeneous research dataset encounters a community hospital using older imaging equipment and serving a demographically distinct patient population, its real-world performance frequently differs from the figures cited in the published validation study. This is a fundamental property of how machine learning generalization works, not a product quality failure. But it is information that procurement teams need before committing to multi-year contracts, and it is rarely volunteered by vendors unless directly requested.
Procurement Insight
A 2022 systematic review published in The Lancet Digital Health found that fewer than one in ten published AI diagnostic studies included prospective validation in a real clinical environment. The other nine relied exclusively on retrospective analysis of historical data. This is relevant for procurement because retrospective validation cannot account for how workflow context, alert fatigue, and clinician behavior affect outcomes in live deployment.
The Evaluation Questions Every Procurement Team Should Ask
Before signing any AI diagnostic contract, require written answers to:
- On what patient population was this model validated, and how does that population’s age distribution, payer mix, and demographic breakdown compare to ours?
- Was this model validated prospectively with real-time clinical decisions made using its output or only retrospectively on historical data where outcomes were already known?
- Has performance been specifically measured on the scanner manufacturers, software versions, and imaging protocols currently in use at our sites?
- What is the contractual process when we identify a performance issue post-deployment, and what are the response time commitments?
- What monitoring infrastructure is in place to detect model performance degradation as our patient population, equipment, and clinical practices evolve?
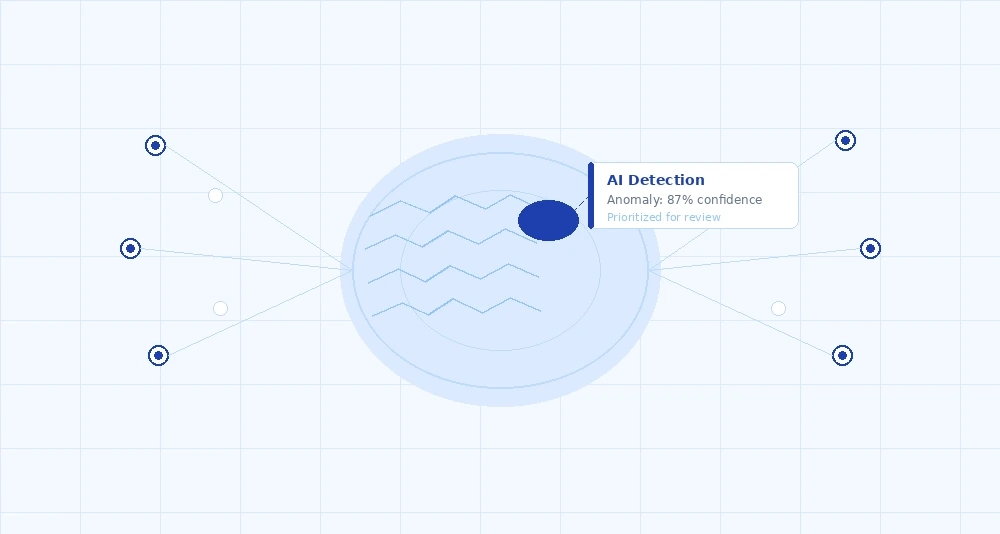
Clinical AI risk analytics are integrated into the EHR workflow for real-time patient risk stratification, alert prioritization, and longitudinal trend monitoring.
The Real Costs of Algorithmic Bias in Clinical AI
Algorithmic bias in healthcare AI is not a theoretical risk being discussed primarily in academic ethics debates. It is a documented operational reality with measurable effects on clinical outcomes, and it deserves substantive attention in any serious vendor evaluation process.
Where Bias Originates in Diagnostic AI Systems
Bias in clinical AI traces almost entirely back to training data. A machine learning model acquires its understanding of diagnostic patterns from the data it was trained on, which means it inherits not just the useful signal in that data but also all the structural characteristics that shaped how that data was collected, documented, and labeled.
Healthcare data is not a neutral record of clinical reality. It reflects decades of decisions about which patient populations had consistent access to care, whose symptoms were thoroughly documented, whose conditions received complete follow-up, and which communities were represented in clinical research. A model trained on that data learns those patterns, including the ones that reflect gaps in care access rather than patterns of disease.
Practical Implications for Organizations Serving Diverse Populations
For health systems serving ethnically diverse or economically mixed patient populations, algorithmic bias is a direct quality and equity concern with operational consequences. A diagnostic AI tool that performs reliably for one patient demographic and underperforms for another creates a measurably unequal diagnostic experience within the same facility. That is both a clinical problem and an organizational liability that boards and legal teams are increasingly aware of.
Before deploying any AI diagnostic tool, organizations should request subgroup performance data that disaggregates accuracy metrics by age group, biological sex, self-reported race and ethnicity, and body mass index where clinically relevant. A vendor who is unable or unwilling to provide this level of detail is communicating something material about the depth of their validation process, even if that communication is unintentional.
Four-pillar AI governance framework for healthcare: algorithmic fairness, explainability, data consent, and continuous equity auditing.
EHR Integration Where Most AI Deployments Actually Struggle
The most commonly underestimated obstacle in healthcare AI deployment is not model accuracy. It is getting the model’s output into the correct location at the correct moment in the clinical workflow, formatted in a way that a clinician working under time pressure will actually notice and act on.

The Alert Fatigue Problem
Organizations that have deployed AI-generated clinical alerts frequently encounter a specific failure pattern: alert acknowledgment rates decline steadily over the months following go-live. Clinicians are not ignoring alerts because the underlying model is performing poorly. They are ignoring them because the signal-to-noise ratio has deteriorated; the alert system generates output more frequently than clinicians can meaningfully respond to, and the entire alert channel gets progressively discounted as a result.
Alert fatigue is a well-documented problem in healthcare informatics that exists independently of AI. AI tools that are deployed without careful calibration for the specific clinical environment and patient volume they will operate in amplify this problem rather than solving it. The technical accuracy of the underlying model matters far less than whether a clinician under pressure trusts the alert enough to act on it at 3 am on a busy unit.
What Sustained Clinical Adoption Actually Requires
AI diagnostic tools that achieve durable clinical adoption share a consistent design characteristic: the model output requires no additional action from the clinician to access. The relevant information appears in the workflow the clinician is already operating in. Currently, it is clinically relevant, formatted in a way that allows a rapid decision without requiring the clinician to interpret probabilistic output under cognitive load.
Tools that require opening a separate interface, manually correlating AI output with the patient chart already open, or learning a new interaction paradigm face an adoption barrier that even strong predictive performance cannot reliably overcome. Workflow integration is not an implementation consideration to be addressed during rollout. It is a clinical adoption determinant that should be evaluated before a contract is signed.
Building an AI Governance Framework Before You Deploy
Healthcare organizations that achieve strong outcomes from AI diagnostic deployments share a consistent characteristic: they treated governance as a prerequisite rather than an afterthought. They defined accountability, monitoring, override processes, and bias evaluation protocols before the first live patient encounter, not during the post-incident review that follows an adverse event.
The WHO guidance on AI ethics for health defines this same principle: governance must be established before deployment, not assembled in response to failures.
The Four Questions Every Organization Must Answer First
Governance prerequisites define these before deployment, not after:
- Who owns model performance post-deployment? When AI output contributes to a clinical decision with a poor outcome, the accountability chain needs to exist in writing before the first patient encounter and not be constructed retrospectively.
- How will performance be monitored over time? A model validated on 2023 data operating in 2026 may encounter patient characteristics, disease patterns, and documentation practices that differ meaningfully from its training environment. Ongoing monitoring is an operational necessity, not an optional service tier.
- What is the clinical override process? Clinicians must retain the authority to override AI recommendations without friction, and override tracking must not create professional pressure to conform to AI output. Both conditions need to be contractually specified.
- How will equity be evaluated after deployment? Pre-deployment bias evaluation is a starting point, not a destination. Patient demographics shift, referral patterns change, and software updates can alter model behavior. Post-deployment equity monitoring should be a standard operational practice, not a one-time audit checkbox.
Contract Terms Healthcare Organizations Should Treat as Non-Negotiable
Organizations negotiating AI diagnostic vendor contracts should require the following as standard terms rather than optional add-ons: access to updated subgroup performance data at least annually; advance notification when the vendor modifies the underlying model architecture or training data; data portability provisions that protect the organization if performance degrades and migration becomes necessary; robust data security architecture that meets requirements for protecting patient health information, including applicable requirements under the Health Insurance Portability and Accountability Act (HIPAA); and explicit specification of which party bears responsibility for ongoing validation as clinical practices and patient populations evolve.
Five Things Every Serious AI Vendor Should Prove Before You Sign
Before committing to any AI diagnostic contract, every healthcare organization should verify these five things in writing. Vendors with rigorous validation processes have this information readily available. Those who cannot provide it are telling you something important.
- Subgroup performance data broken down by race, age, sex, and clinical site do not aggregate accuracy figures, but disaggregated results across your patient demographics
- Hardware-specific validation on the scanner manufacturers and imaging protocols your organization currently uses, performance is not hardware-agnostic
- A defined post-deployment response process with documented timelines and escalation paths, not a generic support queue
- A documented bias evaluation that identifies specific risks found, what was done about them, and how ongoing monitoring works in production
- Clear data provenance covering who owns the patient data used for training and what consent framework governs its use. Organizations that deploy models trained on improperly consented data inherit that liability
Conclusion
AI diagnostic tools are no longer a future investment; they are an active procurement decision. Radiology triage, computational pathology, and EHR-embedded risk stratification are each producing documented results in the right deployment environments. The gap between those results and what most organizations actually experience comes down to three things: how rigorously the tool was evaluated before purchase, how carefully it was integrated into existing clinical workflows, and whether governance was treated as an ongoing operational responsibility rather than a pre-launch checkbox.
At Bitcot, we help healthcare organizations move from vendor evaluation to production deployment with the rigor these decisions require. From EHR integration architecture to bias evaluation frameworks and post-deployment monitoring design, our team brings both technical depth and healthcare domain expertise to every engagement. If your organization is actively evaluating AI diagnostic tools or working through a deployment that is not performing as expected, we are ready to help.
Your practical next step: Use the five vendor evaluation questions in this guide as your opening framework for any AI diagnostic procurement conversation. Then schedule a free 45-minute consultation with Bitcot to review your specific clinical environment, patient population, and technology stack before signing anything.
Frequently Asked Questions
How do I know if an AI diagnostic tool has been validated on a population similar to mine?
Request the vendor’s validation dataset demographics. Compare the age distribution, race and ethnicity breakdown, geographic region, and payer mix of the validation population to your own patient panel. If the vendor cannot provide this information, that signals limited depth in their validation process.
What is the difference between FDA clearance and clinical validation for AI diagnostic tools?
FDA clearance establishes that a device meets specified performance benchmarks and is substantially equivalent to a predicate device. Clinical validation for your specific patient population and clinical environment is a separate, additional requirement. FDA clearance is a floor, not a ceiling for deployment readiness.
How should healthcare organizations think about AI diagnostic tools for rare diseases?
With significant caution. Machine learning models require substantial labeled training examples to generalize reliably. For conditions with limited documented cases, the training data needed for a well-calibrated model may not exist. Rare disease AI tools deserve particularly rigorous validation scrutiny before any clinical deployment.
What does a realistic AI diagnostic implementation timeline look like?
Organizations reporting successful deployments typically spend three to six months on technical integration and testing before going live, followed by six to twelve months of monitored deployment with active performance tracking. Rushing this timeline consistently leads to avoidable problems, including alert fatigue, clinician resistance, and post-launch bias discovery.
How do we evaluate AI diagnostic tools without deep internal AI expertise?
Request reference contacts at comparable health systems that have deployed the tool in production for at least twelve months. Ask specifically about what went wrong during deployment and how the vendor responded. Smooth demos do not predict deployment outcomes honest reference conversations do. Consider partnering with an experienced implementation team for independent evaluation.