
Key Takeaways
- Enterprise DevOps is a cultural and organizational transformation first: tooling decisions follow organizational alignment, not the other way around.
- The CALMS framework (Culture, Automation, Lean, Measurement, Sharing) is the operating model that makes every toolchain decision meaningful at scale.
- A seven-step implementation roadmap, sequenced from organizational alignment through platform engineering maturity, provides a clear starting point and execution order.
- DevSecOps, full-stack observability, and progressive delivery are the three capabilities most consistently absent from failed enterprise transformations across fintech and healthcare technology organizations.
- DORA metrics, including deployment frequency, lead time for changes, change failure rate, failed deployment recovery time, and rework rate, are the most reliable delivery health indicators available and should be baselined before any tooling decision is made.
- Elite DevOps organizations consistently outperform on delivery velocity, reliability, and engineering efficiency within 12 months of disciplined implementation, according to the DORA State of DevOps research program.
Introduction
According to the DORA State of DevOps research program, which draws on over a decade of data from tens of thousands of engineering professionals globally, elite-performing organizations deploy software on demand, often multiple times per day, while low performers ship monthly or quarterly. That gap is not explained by budget or headcount. It is explained by delivery architecture. Enterprise DevOps is the organizational and technical discipline that closes that gap: it unifies development, security, and operations into a single, observable, continuously improving system built to hold under the pressure of distributed teams, legacy constraints, and complex infrastructure.
This guide is written for CTOs, VPs of Engineering, and technical leaders at scaling organizations, including those in fintech, healthcare technology, and SaaS, who are managing real delivery risk every sprint. It covers the CALMS framework, a sequenced seven-step implementation roadmap, and the measurement model that turns a one-time initiative into a compounding competitive advantage. If your team is past theory and ready to execute, this is where to start.
What Is Enterprise DevOps and Why Does It Behave Differently at Scale?
Enterprise DevOps is not a tool purchase, a rebranded Jenkins setup, or a direct equivalent of the DevOps practices that work cleanly inside a 15-person startup. At enterprise scale, it is the organizational and technical unification of software delivery, connecting development, security, operations, and business outcomes into a single, auditable, continuously improving system. The complexity introduced by distributed teams, multi-cloud infrastructure, legacy codebases, and governance requirements creates a fundamentally different operating environment than what smaller teams face.
One of the most persistent misconceptions at the leadership level is treating CI/CD and DevOps as interchangeable concepts. They are not. Understanding the relationship between CI/CD and DevOps is foundational before any tooling evaluation begins. DevOps is the cultural and organizational operating model. CI/CD is the technical delivery mechanism that expresses that model in working pipelines.
What Is the CALMS Framework and Why Does It Matter?
The CALMS framework is the operating model that makes enterprise DevOps tooling meaningful. It was formalized by DevOps practitioners as a maturity framework precisely because a toolchain without organizational principles behind it produces no lasting change. CALMS stands for Culture, Automation, Lean, Measurement, and Sharing.
- Culture creates shared accountability across development, operations, and security so that quality and reliability are everyone’s responsibility, not a handoff between departments.
- Automation removes human toil and error from repeatable processes, from builds and tests to deployment and infrastructure provisioning.
- Lean thinking eliminates waste in the delivery pipeline by identifying and removing steps that add delay without adding value.
- Measurement drives decisions with real data: DORA metrics, deployment frequency, and reliability indicators rather than instinct or opinion.
- Sharing prevents knowledge from re-siloing into functional teams the moment transformation momentum slows, which it always will without a deliberate mechanism to prevent it.
As Gene Kim, co-author of The DevOps Handbook, has noted: in high-performing organizations, quality, availability, and reliability are part of everyone’s job every day, not the responsibility of individual departments. Every enterprise DevOps transformation that fails does so because one or more of these pillars was treated as optional.
What Does a Failed DevOps Transformation Actually Cost?
The cost of delivery fragility has a number, and it is rarely discussed honestly before a transformation begins. According to Gartner research on IT infrastructure performance, unplanned downtime carries direct costs that compound rapidly across finance, healthcare, and e-commerce platforms. Independent field research from EMA Research has placed the average enterprise downtime cost above $14,000 per minute for large organizations, significantly higher than the figures cited in older industry studies.
The indirect cost, covering developer attrition, accumulated technical debt, slowed feature velocity, and lost market position, is typically three to five times the direct figure and far harder to attribute on a profit and loss statement. According to McKinsey’s Developer Velocity research, engineering teams at organizations with immature delivery practices spend between 40% and 50% of their time on unplanned work and rework rather than building forward progress.
For a funded enterprise carrying growth-stage capital, this is not an operational efficiency problem. It is a capital allocation problem. The roadmap below addresses it directly.
The Enterprise DevOps Implementation Roadmap
Most organizations understand what DevOps is in theory. The failure point is almost always execution sequencing: doing the right things in the wrong order, or skipping foundational steps because standing up new tooling feels faster. The roadmap below is sequenced deliberately. Each step builds on the last. Organizational alignment before architecture. Architecture before security embedding. Observability before progressive delivery. There is a compounding logic to this order that reflects how durable transformations actually happen inside large organizations.
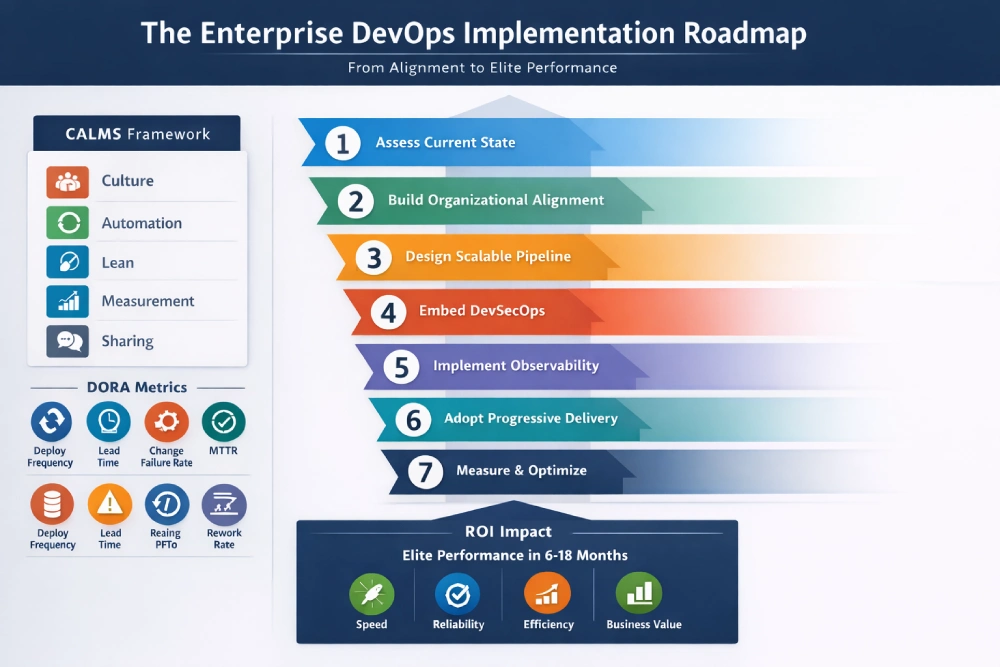
Step 1: Assess Your Current Delivery State Before Building Anything
Before any tool is evaluated or any team is restructured, you need a clear-eyed view of where you actually stand. The starting point is your DORA baseline: deployment frequency, lead time for changes, change failure rate, failed deployment recovery time, and rework rate. According to DORA’s published research tiers, if your change failure rate exceeds 15% or your recovery time after failed deployments is measured in hours rather than minutes, the problem is structural, not instrumental. Buying a new CI/CD tool will not fix it.
What a thorough assessment typically surfaces falls into three categories. Pipeline fragility: builds that break frequently, manual approval gates that exist for bureaucratic rather than governance reasons, and no real-time visibility into deployment status. Environment drift: dev, staging, and production environments that behave inconsistently, producing the classic “works on my machine” failure pattern at a scale that affects every release. And security embedded at the end of the cycle rather than continuously through the pipeline. Most organizations find at least two of these three. Document all findings from this assessment. It becomes the brief that prevents wasted effort in the first six months.
Step 2: Build Organizational Alignment Before You Touch Tooling
This is where most enterprise DevOps implementations die quietly. Teams invest in Kubernetes, stand up GitHub Actions pipelines, and license observability platforms. Six months later, nothing has fundamentally changed because organizational change management was treated as secondary to tooling. It does not work that way.
Organizational alignment in practice means three things. First, a genuine executive sponsor who owns outcomes and can break ties when development and operations priorities conflict. Second, shared KPIs between engineering, security, and product that make speed and stability complementary goals rather than competing ones. Third, a DevOps Center of Excellence: a small, senior team responsible for setting standards, governing toolchain decisions, and actively reducing friction in the inner development loop so that developer experience does not degrade under the weight of organizational change.
The team structure underneath the CoE should follow the Team Topologies model developed by Matthew Skelton and Manuel Pais, which defines four team types: stream-aligned teams that own end-to-end delivery of a product or service, platform teams that build and maintain the internal developer platform, enabling teams that work temporarily alongside stream-aligned teams to build missing capabilities, and complicated subsystem teams that own components requiring deep specialist expertise. Getting this structure right before the toolchain is built prevents the permanent coordination overhead that consistently derails enterprise DevOps initiatives at scale.

Step 3: Design Your Pipeline Architecture for Enterprise Scale
With alignment established, the delivery system can be designed for your actual scale. Source control strategy comes first. Trunk-based development outperforms GitFlow for teams optimizing deployment frequency. The key enabler at enterprise scale is feature flags: tools like LaunchDarkly or Unleash allow incomplete features to live in the trunk without being visible to end users, eliminating the branch complexity that GitFlow creates and the merge conflicts that slow large teams down.
With branching resolved, the next layer is continuous integration and deployment automation. Every commit should trigger an automated build and test cycle. GitHub Actions, GitLab CI, and CircleCI all handle this at enterprise scale. The architectural priority is feedback loop speed: a CI pipeline that takes 45 minutes is a productivity tax that compounds across hundreds of daily commits. According to McKinsey’s software productivity research, elite teams achieve sub-10-minute CI feedback through parallel test execution and build caching.
Here is how the leading enterprise CI/CD platforms compare on the dimensions that matter most to technical decision-makers:
| Platform | Enterprise Security | Native Kubernetes | Pricing Model | Self-Hosted Option |
|---|---|---|---|---|
| GitHub Actions | OIDC, secret scanning, audit log | Good (via Actions) | Per-minute compute | GitHub Enterprise Server |
| GitLab CI | Built-in SAST/DAST, compliance pipelines | Excellent (built-in) | Seat-based | GitLab Self-Managed |
| CircleCI | Audit log, RBAC, IP ranges | Good (orbs) | Per-compute | CircleCI Server |
| Jenkins | Plugin-dependent | Plugin-dependent | Free (infrastructure cost) | Self-hosted only |
For the delivery layer, Kubernetes managed via AWS EKS, Google GKE, or Azure AKS is the enterprise standard for containerized workloads. Docker containers package application code with all dependencies into portable, consistent units that eliminate environment drift. ArgoCD or Flux handle GitOps-based deployments, where infrastructure state is declared in version-controlled repositories and continuously reconciled, removing manual CLI commands from the deployment process entirely. Terraform remains the dominant tool for multi-cloud infrastructure as code, with Pulumi gaining traction for teams that prefer writing infrastructure definitions in TypeScript or Python. Infrastructure should be version-controlled, peer-reviewed through pull requests, and deployed through the same pipeline as application code.
Step 4: Embed Security as a First-Class Pipeline Citizen
Security in a mature DevOps pipeline is not a gate at the end of the release cycle. It is a continuous property of the pipeline itself. Shifting security left means embedding automated checks at every stage from commit to deployment. Static Application Security Testing tools like Checkmarx or Semgrep scan code on every commit before human review begins. Software Composition Analysis tools like Snyk continuously audit open-source dependencies for known vulnerabilities: given that the average enterprise application contains 40% to 60% open-source components, according to Synopsys Open Source Security and Risk Analysis, this is not optional. Container scanning tools like Trivy or Grype check images before they reach the registry. Secrets management must be centralized through tools like HashiCorp Vault or AWS Secrets Manager. Secrets stored in environment variables or source control repositories represent a well-documented category of risk that has caused public security incidents at organizations that had every reason to know better.
Step 5: Build Full-Stack Observability Into the System
Monitoring tells you something is broken. Observability tells you why: specifically which service, which dependency, which change, and what the blast radius is. In a distributed, microservices-based enterprise architecture, you need signal coverage across three types: metrics (quantitative measurements of system behavior), logs (discrete event records), and traces (end-to-end request journeys across service boundaries).
As Nicole Forsgren, PhD, co-author of Accelerate: The Science of Lean Software and DevOps, has consistently found across her research: high-performing teams achieve both speed and stability simultaneously through strong technical practices, not by trading one off against the other. Observability is what makes that simultaneity possible. The OpenTelemetry standard has become the industry’s vendor-neutral instrumentation layer, preventing observability vendor lock-in. For the data platform layer, the Grafana stack (Prometheus for metrics, Loki for logs, Tempo for traces) is the dominant open-source choice. Datadog and New Relic offer managed alternatives with strong Kubernetes integration and lower operational overhead.
The most important architectural decision is not which tool to use. It is ensuring that observability is instrumented from day one of service development, not retrofitted after a production incident. SRE teams at mature organizations use this telemetry to define and track Service Level Objectives: customer-facing reliability commitments that connect engineering performance directly to business outcomes.
Step 6: Implement Progressive Delivery to Contain Release Risk
With a secure, observable pipeline in place, you can deploy with genuine confidence. Progressive delivery separates deployment from release, which is one of the most powerful architectural distinctions in modern software delivery. Canary deployments route a small percentage of traffic, typically 1% to 5%, to a new version while the majority stays on the current stable version. Feature flags via LaunchDarkly or Unleash allow code to ship to production but activate only for specific user segments or percentage rollouts under your control. Blue-green deployments maintain two identical production environments and switch traffic at the load balancer, enabling instant rollback without redeployment.
Tools like Flagger can automate canary analysis: if error rate or latency metrics degrade beyond a defined threshold as the canary percentage increases, the rollout is automatically halted and rolled back without requiring a human to be awake to catch it. For enterprise platforms handling significant transaction volumes, this is how you eliminate release night war rooms. Releases become routine, reversible, and measurable rather than existential events that the entire engineering leadership monitors with anxiety.
Step 7: Measure, Iterate, and Build Toward Platform Engineering Maturity
Eliminating release anxiety is a milestone, not a finish line. What comes next is building the measurement discipline that turns a one-time transformation into a permanent competitive advantage. Establish a quarterly review cycle where you reassess your DORA metrics, review blameless post-mortem outputs from production incidents, and evaluate your toolchain against emerging options. Moving from low to medium DORA performance typically takes 6 to 12 months of focused execution. Moving from medium to elite performance is an 18 to 36-month organizational journey depending on legacy system complexity and team scale.
The natural evolution from a mature DevOps practice leads to platform engineering: where DevOps asks “how do we build better pipelines?”, platform engineering asks “how do we build an internal developer platform that makes every engineering team faster by default?” Platform teams build self-service infrastructure provisioning, golden path templates, and internal developer portals using frameworks like Spotify’s Backstage, which reduce cognitive load on product teams while maintaining governance standards centrally. Value stream management gives leadership visibility into end-to-end delivery flow from idea to production and is the natural complement to platform engineering at high and elite DORA tiers. For a complete framework on measuring DevOps maturity outcomes, Bitcot’s DevOps ROI measurement guide covers each metric tier with specific calculation models.
How Bitcot Helps Enterprise Organizations Implement DevOps
Working with engineering organizations across healthcare technology and fintech, primarily in San Diego and across California, a pattern surfaces consistently: teams that struggle most with DevOps transformation are not the ones with the oldest infrastructure. They are the ones that started with tooling before they resolved team structure. A fintech client came to us with a functioning Kubernetes cluster, automated deployments, and a Datadog instance. Their change failure rate was still above 20% because stream-aligned ownership had never been defined. Three engineering teams were deploying to the same service with no agreed interface contract and no shared on-call rotation. The toolchain was sound. The organizational model was not. The fix was not technical. What we see across engagements is that the inner development loop is where velocity actually lives or dies, and no amount of pipeline automation compensates for unclear ownership. Platform engineering only compounds value once team topology is right. Get that sequencing wrong and the toolchain becomes another layer of complexity to manage rather than a source of acceleration.

Conclusion
Enterprise DevOps transformation is not a project with a defined end state. It is an ongoing operating capability that either compounds your engineering advantage or quietly erodes it. The seven-step roadmap in this guide is sequenced to reflect how real, durable transformations actually happen: organizational alignment before architecture, security embedded throughout rather than bolted on at the end, observability instrumented from day one, and progressive delivery making releases routine rather than existential.
According to DORA’s research, the gap between elite and low-performing software delivery organizations is measurable, documented, and growing every year. The teams moving fastest right now are not doing so because they found a better tool. They made a deliberate architectural decision, executed it with senior engineering talent, and measured outcomes relentlessly against meaningful benchmarks. If your organization is ready to move from diagnosis to execution, the next step is a structured assessment of where your delivery system actually stands today.
Frequently Asked Questions
How long does a full enterprise DevOps implementation realistically take?
A foundational implementation – pipeline architecture, IaC setup, observability, and team alignment – typically takes 3 to 6 months for a focused organization with genuine leadership commitment. Reaching Medium DORA performance takes 6 to 12 months.
Reaching Elite performance is an 18 to 36-month organizational journey depending on legacy system complexity and team size. Organizations that rush this process create technical debt faster than they eliminate it.
The question to ask is not “how fast can we implement DevOps?” but “what is the cost of each additional month of delay?”
What is a realistic total cost of ownership for an enterprise DevOps stack?
TCO depends on scale, team size, cloud provider, and whether you build on open-source or managed services. A mid-market enterprise of 200 to 500 engineers running managed Kubernetes, a modern CI/CD platform, enterprise observability,
and secrets management can expect infrastructure and tooling costs in the $120,000 to $300,000 annual range. Engineering labor to build and maintain the platform is typically the dominant cost – often 3 to 5 times the tooling spend.
The more financially relevant question is what your current deployment risk, incident costs, and developer productivity losses are costing per quarter compared to that investment.
How do we implement DevOps in a heavily regulated industry?
Regulated environments – HIPAA, SOC 2, PCI-DSS, ISO 27001 – require DevSecOps architecture from day one, not retrofitted later. This means continuous compliance built directly into the pipeline: audit-ready automated checks in CI, role-based access controls, centralized secrets management,
and container image scanning before deployment. Done correctly, compliance becomes a continuous, automated, auditable property of every deployment rather than a resource-intensive quarterly event. Organizations that design for compliance from the beginning spend significantly less time and money than those who retrofit it.
Should we build our DevOps capability in-house or work with an external partner?
The answer for most enterprises is both, in sequence. External partners with genuine senior-level DevOps expertise accelerate architectural design and initial implementation significantly – they have solved the specific failure modes you are about to encounter, multiple times.
Internal teams own long-term operations, continuous improvement, and organizational knowledge. Enterprises that outsource DevOps entirely create permanent vendor dependency. Enterprises that build it entirely internally from scratch typically lose 12 to 18 months to avoidable mistakes.
The right partnership model builds internal capability during the engagement, not after it ends.
How do we manage DevOps across globally distributed engineering teams?
Distributed DevOps requires investment in asynchronous tooling and explicit process documentation. GitOps is particularly well-suited to distributed teams because infrastructure state is always declared in version-controlled repositories
– any team member in any timezone can see the current state of the system and understand how any change was made and by whom. On-call rotations, incident response runbooks, and escalation procedures need to be documented and systemized rather than held in individual engineers’ heads.
Async-first communication combined with clear process ownership prevents the coordination gaps that cause incidents in distributed environments.
What is the relationship between DevOps and platform engineering?
Platform engineering is the organizational evolution that high-maturity DevOps teams reach naturally, typically at the Medium-to-High DORA performance transition. Where DevOps asks “how do we build better delivery pipelines?”,
platform engineering asks “how do we build an internal developer platform that makes every product team faster by default, without them having to think about infrastructure?” Platform teams use frameworks like Backstage from Spotify to build internal developer portals with self-service infrastructure, golden path templates,
and service catalogs. Most enterprises should not target platform engineering on day one – it’s the right destination after foundational DevOps practices are mature and stable.
How do we measure ROI on a DevOps transformation investment?
Measure across four dimensions simultaneously. Delivery velocity – lead time for changes and deployment frequency directly correlate with revenue-generating feature output. Reliability – MTTR and change failure rate determine the operational cost of incidents.
Engineering efficiency – the ratio of planned to unplanned work determines how much of your payroll is producing forward progress versus fighting fires. Business outcomes – release-to-revenue cycle time and customer-facing uptime connect engineering performance to commercial results.
Organizations that track all four dimensions report 20 to 30% reductions in time-to-market and 40 to 60% reductions in production incident frequency within 12 months of disciplined implementation.











