Key Takeaways
- Near-universal EHR adoption has not solved healthcare’s data problem patient records still cannot move reliably across system boundaries.
- Health data aggregation bridges that gap through seven stages: extraction, ingestion, validation, identity matching, normalization, storage, and downstream serving.
- FHIR R4 standardizes the API layer but leaves semantic inconsistencies and patient matching challenges unresolved.
- Value-based and accountable care programs depend on population-level insights that fragmented systems simply cannot deliver.
- The real challenge is not connecting EHR systems it is ensuring the resulting data is clinically consistent and reliable enough for care decisions.
Introduction
EHR adoption among U.S. hospitals has reached near-universal levels, according to the Office of the National Coordinator for Health Information Technology. That figure is often cited as proof that healthcare’s data infrastructure problem is solved. It is not.
Adoption means hospitals are generating structured clinical data. It does not mean that data is accessible across the system boundaries where care decisions are actually made. The gap between those two realities is exactly what healthcare data aggregation is designed to close.
Most explanations of aggregation describe the standards involved FHIR, HL7 without showing the actual process. This article traces the complete data journey step by step: from extraction through identity matching, normalization, and storage, to the point where a clinician in a different system can finally query a patient’s record. Healthcare organizations in San Diego and across California have found this kind of grounded understanding essential to evaluating and governing integration programs effectively.
What Is Healthcare Data Aggregation and Why the Problem Persists
Healthcare data aggregation is the process of collecting patient clinical, administrative, and operational data from multiple disconnected source systems, standardizing it into a consistent format, and making it available to downstream clinical and analytical applications through a unified interface. The goal is a single, accurate, and complete view of a patient’s health information regardless of which systems generated it or how many providers were involved in their care.
Understanding why this problem persists despite widespread EHR adoption requires a brief look at how hospital data environments actually develop over time. Most large health systems did not purchase all their software from a single vendor at a single point in time. They grew through acquisitions, merged with other health systems that had different EHR vendors already in place, added specialty systems (cardiology, oncology, radiology) that integrated poorly with the primary EHR, and onboarded digital health programs that generate their own data streams. The result is that a single health system of moderate size may operate five, ten, or more distinct clinical information systems, each using different data models, different clinical code sets, and different patient identifier formats.
The operational consequences for clinical staff are concrete. A hospitalist reviewing a patient admitted overnight cannot see the outpatient medication changes made by the patient’s cardiologist last week if those records live in a different system. A care coordinator building a discharge plan cannot see the specialist notes from a referral visit handled at an affiliated clinic on a separate EHR. Those gaps in clinical information do not just create friction: they generate redundant testing, missed medication interactions, and care coordination delays that have measurable effects on patient outcomes and operational efficiency.
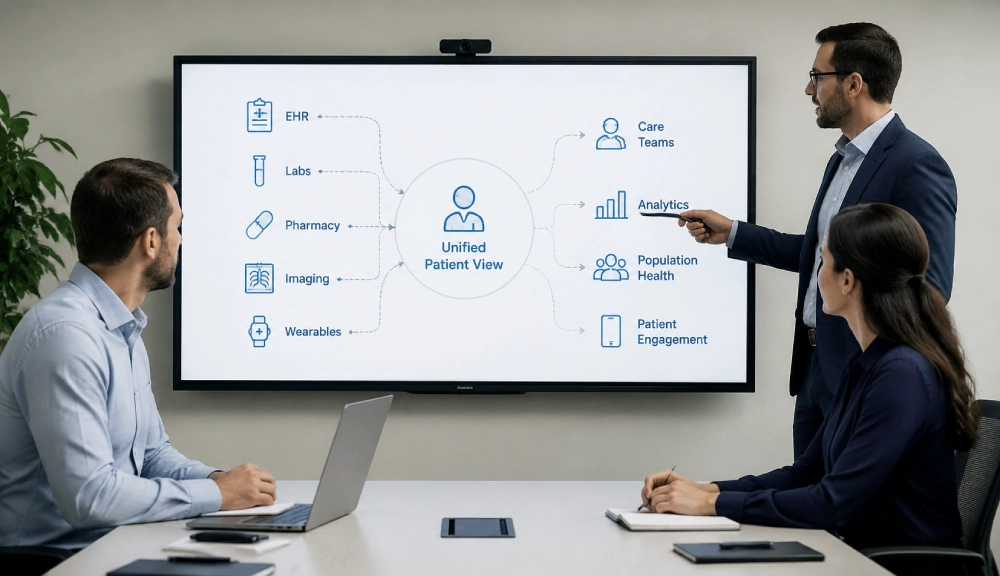
How Healthcare Data Aggregation Works: Tracing a Patient Record Through the System
The mechanics of healthcare data aggregation are best understood by following a single patient record from the moment it is created in a source system to the moment it is available to a downstream clinician or application. Each stage in that journey involves specific technical processes and introduces specific failure modes that determine the overall reliability of the aggregated data.
Stage 1: Data originates in source systems. A patient visit, lab result, medication order, or clinical note is entered or generated in a source EHR, laboratory information system, or specialty platform. At this stage, the data exists in the source system’s native format, using that system’s patient identifiers, clinical code sets, and data model. It is not yet accessible to any other system.
Stage 2: Extraction from the source system. The health data aggregator establishes a connection to each source system through the protocol that the system supports. Modern EHR systems that comply with the 21st Century Cures Act expose FHIR R4 APIs that the aggregator queries on a scheduled or event-driven basis. Older systems may generate HL7 v2 message streams that the aggregator receives in real time through an interface engine. Some legacy systems support neither standard and require custom database extracts or file-based exports on a batch schedule. The aggregator must maintain a separate extraction connector for each source system type, each with its own authentication, connection management, and error handling logic.
Stage 3: Ingestion and schema validation. Incoming records enter the aggregator’s ingestion layer, where they are validated against a defined schema before any further processing. Records that conform to the expected format proceed to the next stage. Records with missing required fields, unexpected values, or structural anomalies are routed to a quarantine state where they are logged and flagged for review rather than silently dropped. This validation boundary is where data quality problems introduced by the source system are captured rather than propagated.
Stage 4: Patient identity matching. The same patient almost certainly exists under a different identifier in each source system. The aggregator’s patient matching service evaluates incoming records against a master patient index using demographic attributes, such as name, date of birth, address, and phone number, to determine whether the incoming record belongs to a patient already known to the aggregator. When the matching algorithm reaches sufficient confidence, the record is linked to the existing patient identity. When confidence is insufficient, the record is flagged for human review. Identity matching errors, both false merges and false splits, are among the most consequential data quality failures in health data aggregation because they propagate into every downstream use of the affected patient’s record.
Stage 5: Clinical code normalization. Clinical concepts in the incoming record are mapped to standardized terminologies. A diagnosis code from one EHR vendor’s proprietary code set is translated to ICD-10. A laboratory result identified by a local code is mapped to the corresponding LOINC code. A medication name is resolved to an RxNorm concept. This normalization step is what makes cross-system analysis possible: without it, a query for “patients with a diagnosis of hypertension” would miss every patient whose record uses a different code or free-text entry for the same clinical concept.
Stage 6: Storage in the aggregated data platform. The normalized, identity-resolved record is written to the aggregator’s storage layer. Most mature health data management systems maintain two storage structures: a FHIR-native clinical data store for patient-level queries and clinical application access, and a columnar analytics warehouse for population-level queries and reporting. The same normalized record is written to both, enabling the platform to support both individual care coordination use cases and population health analytics from the same underlying data.
Stage 7: Data served to downstream consumers. Applications, analytics tools, and clinical workflows query the aggregated data through the serving layer, which exposes FHIR-compliant APIs for clinical access and direct query interfaces for analytics. From the consumer’s perspective, all of a patient’s clinical history from all connected source systems appears as a single, unified record. The seven stages that produced that record are invisible to the end user, as they should be.
EHR Data Integration Methods: How Connections to Source Systems Actually Work
The method used to extract data from a source EHR depends almost entirely on what that system supports, not on what the aggregator prefers. Understanding the range of integration methods in use helps set realistic expectations for both the timeline and the complexity of connecting a given set of source systems.
HL7 v2 messaging remains the dominant protocol in production healthcare environments, particularly for high-frequency clinical events like admissions, discharges, transfers, lab results, and order messages. HL7 v2 messages are pipe-delimited text transmissions that flow through real-time message streams. Every major EHR system generates them, and most hospitals have existing infrastructure for routing them. The limitation is that HL7 v2 was not designed for query-based access: it pushes event notifications rather than enabling an aggregator to retrieve a complete patient record on demand.
FHIR REST APIs enable the aggregator to query a source EHR for structured patient data on demand, using a standardized resource model. For OpenEMR development and other certified EHR implementations, FHIR R4 API access is now a mandated requirement following the 21st Century Cures Act. FHIR connections give the aggregator the ability to retrieve a complete patient record, search for patients matching specific criteria, and subscribe to change notifications when a patient’s data is updated.
Direct database connections and file exports are the integration method of last resort for legacy systems that support neither HL7 v2 streaming nor FHIR APIs. These systems may export clinical data as flat files on a nightly or weekly batch schedule, or may permit direct read access to their underlying database. Both approaches are fragile: flat file formats change without notice, and direct database access creates tight coupling between the aggregator and the source system’s internal schema, making upgrades to either system a high-risk event.
FHIR Data Standards in Healthcare: What the Mandate Changed and What It Did Not
The HL7 FHIR standard defines a set of structured data resources and a REST API specification for exchanging health data. The 21st Century Cures Act information blocking rules that took effect in 2021 required all certified EHR systems to expose FHIR R4 APIs that provide patient data access without charge, representing the most significant regulatory change in healthcare interoperability in over a decade.
What the FHIR mandate changed is the extraction layer. Before it, connecting to a new EHR system required custom integration work specific to that vendor’s proprietary APIs or message formats. After it, a health data aggregator with an FHIR R4 client can connect to any certified EHR using the same API pattern, dramatically reducing the per-system integration cost for new connections.
What the FHIR mandate did not change is everything that happens after extraction. FHIR defines the format in which data is exchanged, not the consistency of the clinical content within that format. Two EHR systems may both return a valid FHIR Patient resource and a valid FHIR Observation resource for a blood pressure reading while using different LOINC codes, different unit conventions, and different reference range definitions. The aggregator must normalize those differences in stage five of the data journey, regardless of whether the data arrived via FHIR or HL7 v2. The standard changed the envelope; the normalization challenge inside the envelope remains.

What Are the Biggest Challenges in Healthcare Data Integration Systems
Understanding how healthcare data aggregation works also means understanding where it characteristically goes wrong. The challenges in healthcare data integration systems are not random: they cluster around a predictable set of problems that arise from the nature of clinical data and the history of how healthcare IT systems were built.
Patient identity matching across disconnected systems. There is no universal patient identifier in the United States healthcare system. Each organization assigns its own medical record number, and the same patient may have different names, addresses, or date-of-birth representations in different systems, due to data entry variation, legal name changes, or transcription errors. Probabilistic matching algorithms can handle most cases, but the edge cases require human review, and every unresolved mismatch results in either a false merge (two patients’ records incorrectly combined) or a false split (one patient’s records incorrectly treated as belonging to two people). Both error types have clinical consequences when they affect active patient care.
Semantic inconsistency in clinical terminology. Healthcare uses multiple overlapping clinical coding systems: ICD-10 for diagnoses, LOINC for laboratory tests, RxNorm for medications, SNOMED CT for clinical concepts, and numerous local facility-specific codes that map imprecisely to the standard sets. A patient’s “type 2 diabetes” may be represented by a different code in each EHR system that has ever documented it. Normalizing these representations to a consistent internal concept requires a terminology service with current mappings maintained through regular update cycles, because the standard code sets themselves are revised annually.
Data freshness requirements vary across use cases. A sepsis early warning system needs vital signs and laboratory data with a latency measured in minutes. A population health dashboard showing care gaps across a patient panel can tolerate data that is a day old. A billing reconciliation system processes claims on a weekly batch cycle. A single healthcare data pipeline that applies one data freshness model to all of these use cases will either over-engineer the infrastructure for low-urgency use cases or fail to meet the latency requirements of time-sensitive clinical applications.
Source system variability and unannounced changes. EHR vendors release software updates that alter message formats, add or remove fields, and change clinical code mappings without always notifying the downstream systems consuming their output. According to AHRQ research on health IT implementation, interface breakage from unannounced source system changes is among the most common operational disruptions in health data integration programs. An aggregator without a schema validation layer at the ingestion boundary will silently ingest malformed records until the error surfaces downstream, often after weeks of contaminated data have entered the platform.

How California Hospitals Are Advancing Patient Data Integration
California’s healthcare ecosystem has some of the strongest organizational incentives for completing health data integration. The state has a high concentration of accountable care organizations (ACOs) and value-based care programs, both of which require population-level clinical data that fragmented EHR environments cannot produce. For a health system participating in a value-based contract, the inability to measure care quality and outcomes across all of a patient’s interactions within the network is a direct reimbursement risk, not just a technical inconvenience.
In Los Angeles, large integrated health systems have been building centralized health data platforms to support their ACO programs, connecting dozens of affiliated clinics and specialty practices that operate on different EHR systems into a single analytics environment. The integration work is not optional for these organizations: their contractual commitments depend on the data completeness that only a functioning aggregation layer can provide.
San Diego’s healthcare organizations face the same imperative, compounded by the city’s distinctive mix of academic medical centers, community health systems, and a large veteran health network, each operating independently but increasingly expected to coordinate care for shared patient populations. Software development in San Diego for healthcare contexts has increasingly centered on the data integration infrastructure that makes that coordination possible, including the AI/ML development layers that translate aggregated clinical data into actionable care management insights for clinical teams.
According to McKinsey’s healthcare digital research, the organizations realizing the strongest operational and clinical outcomes from health data integration are those that treated integration not as a one-time project but as an ongoing infrastructure capability, continuously adding source systems and use cases as the platform matures. California’s leading health systems are well along that trajectory.
What We’ve Learned From Healthcare Data Integration Projects
Working with healthcare organizations in San Diego and across California, we observe a consistent gap in how integration programs are understood by different stakeholders. Clinical and IT leadership tend to underestimate the data quality work: they expect that connecting EHR systems will automatically produce usable data, without fully accounting for the patient matching, code normalization, and ingestion validation layers that determine whether connected data is actually reliable. Engineering teams, by contrast, often underestimate the governance requirements: the human review processes, terminology update workflows, and data lineage tracking that keep the platform trustworthy as it scales.
The programs that go well are the ones where both groups have a shared mental model of what the seven stages actually involve and what can go wrong at each one. The telemedicine software development and health data programs where we have seen the clearest path from integration to clinical value are the ones where that shared understanding was established early, before the first system connection was made.

Conclusion
Healthcare data aggregation is not a single technical step. It is a seven-stage process, each with its own failure modes, quality requirements, and operational dependencies, that begins when a patient record is created in a source system and ends when that record is reliably available to a downstream application or clinician who needs it. Understanding the complete journey, rather than just the standards at the extraction layer, is what separates integration programs that deliver durable clinical value from those that create connections without delivering reliable data.
For healthcare organizations evaluating integration investments, the right question is not “how do we connect our EHR systems?” but “how do we ensure that everything that happens between connection and consumption is working correctly?” That shift in framing is where the most consequential decisions in healthcare data architecture actually live.
Frequently Asked Questions
What is healthcare data aggregation?
Healthcare data aggregation is the process of collecting patient clinical, administrative, and operational data from multiple disconnected source systems, such as EHRs, laboratory platforms, pharmacy systems, and claims databases, standardizing it into a consistent format, and making it available through a unified interface for clinical care, analytics, and care coordination applications. As this article explains, the process spans seven stages from extraction through serving, and the quality of the aggregated data depends on what happens at each stage, particularly patient identity matching and clinical code normalization, not just on whether the source systems are technically connected.
What is the difference between HL7 v2 and FHIR for hospital data integration?
HL7 v2 is the older messaging protocol that pushes clinical event notifications in real time through point-to-point streams, and it remains the dominant protocol for high-frequency clinical transactions like lab results and admission messages in most hospital environments. FHIR is a modern REST API standard that enables query-based access to structured patient records on demand, and it became the mandated interface for certified EHR systems following the 21st Century Cures Act in 2021. As this article describes, a health data aggregator typically uses both: HL7 v2 for real-time event streams from systems that support it and FHIR APIs for structured patient record retrieval from certified EHR systems, because different source systems support different protocols regardless of what the aggregator would prefer.
How do hospitals integrate patient data from multiple EHR systems?
Hospitals integrate patient data from multiple EHR systems through a health data aggregator that establishes separate extraction connections to each source system using the protocol that system supports, whether HL7 v2 messaging, FHIR APIs, or batch file exports. As this article traces step by step, the extracted records then pass through ingestion validation, patient identity matching, and clinical code normalization before being stored in a unified data platform that downstream applications and analytics tools query through a single interface. The connection to each source system is only the first stage: the patient matching and normalization stages that follow determine whether the data that emerges from those connections is accurate and clinically useful.
How is health data aggregation used in San Diego healthcare systems?
Healthcare organizations in San Diego are using health data aggregation primarily to support care coordination across the city’s mix of academic medical centers, community health systems, and affiliated specialty practices that operate on different EHR platforms. The strongest driver of integration investment in San Diego is participation in value-based care and accountable care programs, which require population-level clinical data that fragmented EHR environments cannot produce independently. As this article describes, California’s high concentration of ACO programs creates a direct reimbursement incentive for completing the data integration work that many organizations in other markets treat as optional.
Do hospitals need a health data aggregator if they already use a single EHR vendor?
Hospitals that have standardized on a single EHR vendor still need health data aggregation for several common scenarios: affiliated specialty clinics that operate on different systems, laboratories and radiology practices that use separate platforms, digital health programs that generate data outside the primary EHR, and claims data from payers that arrives through separate administrative channels. Even within a single-vendor EHR deployment, different instances at different facilities often use separate databases that do not share patient records automatically. A health data aggregator addresses these gaps by creating a unified data environment that spans all clinical and administrative data sources, regardless of whether the primary EHR vendor is the same across locations.